
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Windows
- Python
- sample
- Git
- MSSQL
- JavaScript
- JS
- API
- Ai
- mariadb
- 구글
- error
- build
- Kibana
- 설정
- ssh
- docker
- Linux
- unity
- AWS
- ChatGPT
- s3
- nodejs
- 영어
- 엘라스틱서치
- logstash
- MySQL
- 유니티
- elasticsearch
- Today
- Total
목록개발 이야기 (320)
가끔 보자, 하늘.
 WSL2 Ububtu에 ollama/deepseek 설치 및 실행
WSL2 Ububtu에 ollama/deepseek 설치 및 실행
https://ollama.com/download/linux 에서 linux 를 선택하면 설치 command 확인 가능curl -fsSL https://ollama.com/install.sh | sh설치가 끝나면 여러 결과 중 "Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service."라는 라인을 볼 수 있다. ollama.service에 필요한 환경변수를 설정!$ vi /etc/systemd/system/ollama.service[Unit]Description=Ollama ServiceAfter=network-online.target[Service]ExecStart..
wsl -l -v로 현재 실행중인 배포판 이름 확인C:\Users\your_account>wsl -l -v NAME STATE VERSION* docker-desktop-data Stopped 2 Ubuntu Running 2 docker-desktop Stopped 2위에서 배포판 이름은 "Ubuntu". wsl을 중단하고 E 드라이브로 이동> wsl --shutdown # wsl 중지> wsl --export Ubuntu E:\wsl\Ubuntu.tar # 배포판 export> wsl --unregister Ubuntu # 기존 배포판 삭제> wsl --i..
 Windows 11/Docker에서 Ubuntu 설치 및 Nvidia 그래픽 카드 연동 절차
Windows 11/Docker에서 Ubuntu 설치 및 Nvidia 그래픽 카드 연동 절차
WSL2 활성화 및 Ubuntu 설치> wsl --install # 설치하기> wsl --update # 최신 버전으로 업데이트> wsl -d ubuntu # 실행하기"https://www.nvidia.com/en-us/drivers/"에서 Nvidia 드라이버 최신 버전으로 설치 후 파워쉘 혹은 cmd에서 "nvidia-smi" 로 설치 정보 확인. (글 작성 시점 기준, NVIDIA-SMI 565.90 / Driver Version: 565.90 / CUDA Version: 12.7 )linux wsl-ubuntu 2.0설치 (https://developer.nvidia.com/cuda-downloads)wsl 에서 위 설치 명령들을 실행$ wget https://developer.download...
 Unity 에서 Firebase 연동하기 - 유저 데이터 저장/불러오기
Unity 에서 Firebase 연동하기 - 유저 데이터 저장/불러오기
아직 익명 로그인만 지원하고 있지만 한 유저의 정보를 firebase realtime database(이하 rtb)에 저장해 보겠습니다.firestore와 rtb 를 선택할 때는 데이터의 복잡성, 규모, 비용등을 고려해야 하지만 일단 싸고 단순한 rtb로 시작하면 좋습니다. 추후 마이그레이션도 그렇게 복잡하지는(케바케인거.. 아시죠 ^^a) 않습니다.우선 firebase 콘솔 왼쪽 화면에서 rtb를 선택해 생성을 시도합니다. 그럼 아래와 같은 주소가 할당됩니다. 그리고 프로젝트 설정 > 일반 > 내 앱 > SDK 설정 및 구성 에서 google-services.json을 (애플 기기 서비스 사용자는 GoogleService-Info.plist파일도 같이) 다운받아 Unity -> Assets 폴더에 덮어..
(인터넷이 연결되지 않는)보안망에서 FastAPI를 이용해 API 서버를 만들고 /docs에 접근하면 swagger ui 가 보이지 않는다. fastapi에서 swagger ui 를 등록된 cdn에 연결해 다운로드를 시도하다 실패해 버린다. 만약 필요없다면 다음과 같이 설정해 /docs로 접속해도 아무런 처리가 되지 않도록 설정할 수 있다.app = FastAPI(docs_url=None, redoc_url=None)swagger ui를 사용하기 위해서는 swagger ui 프로젝트의 dist 폴더 파일만 있으면 된다. (링크)이 파일을 다운받아 fastapi 프로젝트에 포함해 배포하면 됩니다. 설정은 다음과 같다. dist의 파일들을 프로젝트 내의 src/statics에 넣고 다음과 같이 설정한다.fr..
 Unity 에서 Firebase 연동하기 - 초기 설명 및 익명 사용자 허용 설정
Unity 에서 Firebase 연동하기 - 초기 설명 및 익명 사용자 허용 설정
(* 이 글은 unity6, 2024/12 를 기준으로 작성되었습니다.)주로 AWS만 사용하다 혼자 모바일 게임을 준비하다보니 비용이 거의 들지 않는 방법으로 게임 백엔드를 대체할 인프라가 필요해 정리해 보았습니다. AI로 텍스트 결과만 보면서 진행하기 힘드신 분들에게 도움이 되기를 바라며 오랜만에 정리해 봅니다.간단한 설정만으로 사용자 정보를 연동할만한 서비스에 Playfab이나 Firebase가 적당하다고 AI님이 말씀하셔서 그래도 Firebase가 구글 연동에 더 편할 듯(아무런 근거는 없지만..) 해서 선택했습니다.Firebase 홈페이지에서 Unity SDK Package를 다운받고 Firebase Auth 패키지를 설치한 후 https://console.firebase.google.com/ 에..
사내 혹은 개인이 사용하는 git server의 주소가 바뀌었을 때 팁!# 저장소와 연결된 로컬 프로젝트 경로로 이동해 현재 설정된 주소 확인> git remote -v # 원격 저장소 주소로 변경> git remote set-url origin [현재 원격 저장소 주소 or ip]보통 회사에서는 git 서버 주소가 바뀔일이 없고 github를 쓸 때는 더욱 더. 개인 PC에 git 저장소를 만들어 개인 프로젝트들을 주로 여기에 저장해 노트북과 PC간 프로젝트를 공유하다 간혹 공유기 ip 주소 바뀌면 변경해 줘야 한다.요즘은 이런거 llm에 물어보면 바로 대답을 해주니 예전처럼 이렇게 정리하는게 있나 싶다 자기전에 한번 적어본다.
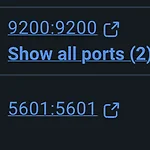 Elasticsearch Docker Desktop으로 실행해보기
Elasticsearch Docker Desktop으로 실행해보기
우선 Docker Desktop에서 Elasticsearch , Kibana 이미지를 찾아 실행합니다. 둘 모두 잘 실행되었다면 kibana로 접속합니다. http://localhost:5601로 접속하면 아래와 같은 화면이 뜹니다. docker 로 둘을 실행하면 서로 다른 네트웍으로 인식하고 elasticsearch에서는 kibana의 원격접속 인증을 위해 elasticsearch에서 발급한 토큰을 입력하라고 요청합니다. elasticsearch docker에 exec 탭에서 아래 커멘드를 입력해 토큰을 생성합니다. bin/elasticsearch-create-enrollment-token --scope kibana이렇게 발급된 코드값을 복사해 kibana 웹 페이지에서 입력합니다. 그럼 아래와 같은 ..