
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- gemini
- unity
- 재테크
- MSSQL
- 바보
- 구글
- Kibana
- 투자
- JavaScript
- Ai
- FLUTTER
- Linux
- 유니티
- 분석
- MySQL
- Windows
- AWS
- elasticsearch
- 주식
- error
- 설정
- LLM
- JS
- app
- ChatGPT
- nodejs
- Python
- docker
- API
- Today
- Total
가끔 보자, 하늘.
LLM 응답 속도 개선 해보기(feat. Qwen) 본문
Python과 자체 배포 Qwen3: LangChain/LangGraph를 활용한 응답 속도 최적화 완전 정복
목차
- 서론: 왜 자체 배포 LLM의 응답 속도가 중요한가?
- LLM 응답 속도의 기본: 추론 과정과 핵심 지표 이해하기
- 1단계 최적화: 파라미터 튜닝으로 즉각적인 속도 향상
- 2단계 최적화: Redis 캐싱으로 반복 요청의 지연 시간 '0'에 가깝게 만들기
- 심화: LangGraph와 Redis를 활용한 에이전트 상태 저장 및 캐싱
- 성능 분석 및 벤치마킹: 최적화 효과 정량화하기
- 결론: 상황에 맞는 최적의 전략 선택 가이드
서론: 왜 자체 배포 LLM의 응답 속도가 중요한가?
최근 몇 년간 인공지능 분야, 특히 대규모 언어 모델(LLM)은 괄목할 만한 발전을 이루었다. OpenAI의 GPT 시리즈가 촉발한 생성형 AI의 물결은 이제 오픈소스 진영으로 확산되어, Llama, Mistral, 그리고 알리바바 클라우드가 선보인 Qwen 시리즈와 같은 강력한 모델들이 연이어 등장하고 있다. 이러한 오픈소스 LLM의 부상은 기업과 개발자에게 새로운 기회의 문을 열어주었다. 더 이상 외부 API에 전적으로 의존하지 않고, 자체 인프라에 모델을 직접 배포(Self-hosting)함으로써 데이터 프라이버시를 완벽하게 통제하고, 장기적인 관점에서 운영 비용을 절감하며, 특정 도메인에 맞게 모델을 자유롭게 커스터마이징할 수 있게 된 것이다.

하지만 이러한 장밋빛 전망 이면에는 '응답 지연(Latency)'이라는 혹독한 현실적 문제가 존재한다. 자체 서버에서 LLM을 운영할 때, 사용자가 질문을 입력한 후 의미 있는 답변을 받기까지 걸리는 시간은 애플리케이션의 성패를 좌우하는 결정적인 요소가 된다. 예를 들어, 고객 서비스 챗봇이 사용자의 질문에 5초 이상 묵묵부답이라면 사용자는 즉시 대화를 포기할 것이다. 개발자를 위한 코드 어시스턴트가 실시간으로 추천 코드를 생성해주지 못한다면 생산성 향상은커녕 오히려 작업 흐름을 방해하는 애물단지가 될 뿐이다. 이처럼 응답 속도는 단순히 기술적 성능 지표를 넘어, 사용자 경험(UX)의 핵심이자 서비스의 가치를 결정하는 척도이다.
이 글의 목표는 명확하다. Python 환경에서 강력한 AI 애플리케이션 개발 프레임워크인 LangChain과 LangGraph를 활용하여, 자체 배포한 Qwen3 모델의 응답 속도를 극적으로 향상시키는 두 가지 핵심 방법론을 심층적으로 탐구하는 것이다. 첫째, 모델의 동작 방식을 제어하는 **파라미터 튜닝**을 통해 즉각적인 성능 개선을 꾀하고, 둘째, 반복적인 요청을 효율적으로 처리하기 위한 **Redis 캐싱** 전략을 도입하여 지연 시간을 획기적으로 단축시키는 방법을 다룬다. 나아가, 각 방법론의 실제 효과를 벤치마킹을 통해 정량적으로 분석하고, 독자들이 자신의 서비스 환경에 맞는 최적의 전략을 선택할 수 있도록 실질적인 가이드를 제공하고자 한다.
LLM 응답 속도의 기본: 추론 과정과 핵심 지표 이해하기
본격적인 최적화 방법론을 논하기에 앞서, LLM이 어떻게 응답을 생성하며 우리는 그 속도를 어떻게 측정해야 하는지에 대한 기본적인 이해가 필요하다. 이 개념들은 최적화의 목표를 명확히 하고, 각 전략이 어떤 원리로 작동하는지 파악하는 데 도움을 줄 것이다.
LLM 추론의 두 단계
LLM의 추론 과정, 즉 응답 생성 과정은 크게 두 단계로 나눌 수 있다. 이 두 단계의 특성을 이해하는 것이 지연 시간 최적화의 첫걸음이다. (Databricks LLM Benchmarking)
- Prefill (입력 처리 단계): 이 단계에서는 사용자가 입력한 프롬프트의 모든 토큰이 모델에 한 번에 입력되어 병렬로 처리된다. 모델은 입력된 컨텍스트 전체를 이해하고, 다음에 생성할 첫 번째 토큰을 준비한다. 따라서 입력 프롬프트의 길이가 길수록(예: 긴 문서 요약, RAG에서 많은 검색 결과 제공) Prefill 단계에 소요되는 시간이 증가한다.
- Decoding (토큰 생성 단계): Prefill 단계가 끝나면, 모델은 자기회귀적(auto-regressive)으로 다음 토큰을 하나씩 생성하기 시작한다. 즉, 첫 번째 토큰을 생성한 후, 그 토큰을 다시 입력의 일부로 간주하여 두 번째 토큰을 예측하고, 이 과정을 응답이 끝날 때까지 반복한다. 생성해야 할 응답의 길이가 길수록 Decoding 단계의 시간이 길어진다.
속도 측정의 핵심 지표
LLM의 응답 속도를 평가할 때는 여러 지표가 사용되지만, 사용자 경험과 직결되는 가장 중요한 두 가지 지표는 다음과 같다. (BentoML - Key metrics for LLM inference)
- TTFT (Time to First Token): 사용자가 요청을 보낸 후, 화면에 첫 번째 응답 토큰이 나타나기까지 걸리는 시간이다. TTFT는 Prefill 단계의 소요 시간과 첫 번째 토큰의 Decoding 시간을 합한 값이다. 이 지표가 낮을수록 사용자는 시스템이 즉시 반응하고 있다고 느끼며, '멈춤'이나 '오류'가 아니라는 심리적 안정감을 얻는다. 실시간 상호작용이 중요한 챗봇 애플리케이션에서 특히 중요하다.
- TPOT (Time per Output Token) / ITL (Inter-Token Latency): 첫 번째 토큰 이후, 다음 토큰들이 생성되는 데 걸리는 평균 시간이다. 이 지표는 Decoding 단계의 효율성을 나타낸다. TPOT가 낮을수록(즉, 초당 생성 토큰 수(TPS)가 높을수록) 텍스트가 끊김 없이 부드럽게 스트리밍되는 것처럼 보인다. 긴 글을 생성하는 작업에서 사용자가 답답함을 느끼지 않게 하려면 낮은 TPOT가 필수적이다.
우리의 최적화 목표는 바로 이 TTFT와 TPOT를 모두 단축시키는 것이다. 파라미터 튜닝은 주로 Decoding 단계에, 캐싱은 Prefill 단계와 전체 요청 과정에 큰 영향을 미치게 된다.
1단계 최적화: 파라미터 튜닝으로 즉각적인 속도 향상
가장 먼저 시도해볼 수 있는 최적화는 코드 몇 줄을 수정하여 모델의 생성 파라미터를 조절하는 것이다. 이는 추가적인 인프라 없이 즉각적인 속도 향상을 기대할 수 있는 가장 기본적인 방법이다.
핵심 원리: 생성 방식의 트레이드오프
LLM의 응답 생성 방식은 크게 '결정론적 생성'과 '샘플링 기반 생성'으로 나뉜다. 이 둘은 속도와 응답의 창의성 사이에서 트레이드오프 관계를 가진다. (Hugging Face - Text Generation Strategies)
- Greedy Search (탐욕 검색): 각 단계에서 가장 확률이 높은 토큰 하나만을 선택하는 방식이다. 추가적인 계산이 거의 없어 가장 빠르지만, 매번 동일한 입력에 동일한 답변을 생성하며, 응답이 다소 단조롭고 예측 가능해질 수 있다. LangChain이나 Transformers 라이브러리에서는 보통 do_sample=False로 설정하여 활성화한다.
- Sampling (샘플링): 확률 분포에 따라 토큰을 무작위로 선택하는 방식이다. temperature(무작위성 조절), top_p(누적 확률 기반 필터링), top_k(상위 K개 토큰 중 선택) 등의 파라미터를 통해 응답의 다양성과 창의성을 높일 수 있다. 하지만 확률 분포 계산 및 샘플링 과정에서 추가적인 연산이 필요하므로 Greedy Search보다 느리다.
따라서, 애플리케이션의 목적에 따라 속도가 최우선이라면 Greedy Search를, 창의적이고 다양한 답변이 필요하다면 샘플링 방식을 선택하는 전략적 접근이 필요하다.
Qwen3 고유 파라미터 활용: enable_thinking
Qwen3 모델은 다른 모델들과 차별화되는 독특하고 강력한 파라미터인 enable_thinking을 제공한다. 이는 모델의 추론 방식을 직접 제어하여 속도와 응답 품질을 조절하는 핵심 스위치 역할을 한다. (Qwen3 Official Blog)
- enable_thinking=True (기본값): 이 모드에서 Qwen3는 복잡한 질문에 답하기 위해 내부적으로 '생각'하는 과정을 거친다. 이는 CoT(Chain-of-Thought)와 유사한 방식으로, 단계별 추론 과정을 생성하여 더 논리적이고 정확한 답변을 도출한다. 당연히 이 '생각' 과정은 추가적인 연산을 요구하므로 응답 속도는 느려진다. 복잡한 추론, 수학 문제 해결, 코드 생성과 같은 작업에 적합하다.
- enable_thinking=False: 이 모드에서는 내부적인 추론 과정 없이 바로 최종 답변을 생성한다. 단순 질의응답, 정보 요약, 감성 분석 등 깊은 추론이 필요 없는 작업에서 이 옵션을 사용하면 응답 속도를 크게 향상시킬 수 있다.
이 파라미터는 Qwen3의 성능을 최대한 활용하기 위해 반드시 이해하고 사용해야 할 중요한 기능이다.
LangChain을 이용한 실제 구현 가이드
LangChain 프레임워크를 사용하면 이러한 생성 파라미터를 쉽게 설정할 수 있다. vLLM과 같은 추론 서버와 함께 OpenAILike 래퍼를 사용하거나, 직접 모델을 로드하는 HuggingFacePipeline을 사용할 때 generation_config 또는 model_kwargs를 통해 파라미터를 전달하면 된다.
다음은 속도 극대화를 위해 Greedy Search를 사용하고 'thinking' 과정을 비활성화하는 예시 코드이다.
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, GenerationConfig
# Qwen3 모델 및 토크나이저 로드
model_id = "Qwen/Qwen3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
# 속도 최적화를 위한 GenerationConfig 설정
# do_sample=False로 Greedy Search 활성화
generation_config = GenerationConfig(
do_sample=False,
max_new_tokens=512,
# 참고: OpenAILike 래퍼에서는 chat_template_kwargs={"enable_thinking": False} 와 같이 전달
)
# LangChain 파이프라인 생성
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
generation_config=generation_config
)
llm = HuggingFacePipeline(pipeline=pipe)
# 최적화된 LLM 실행
prompt = "대한민국의 수도는 어디인가요?"
response = llm.invoke(prompt)
print(response)
# vLLM과 OpenAILike 사용 시 예시 (참고)
# from langchain_openai import OpenAILike
# llm = OpenAILike(
# model="Qwen/Qwen3-8B-Instruct",
# api_base="http://localhost:8000/v1",
# api_key="EMPTY",
# temperature=0, # do_sample=False와 유사한 효과
# model_kwargs={"stop": ["<|im_end|>"], "extra_body": {"enable_thinking": False}}
# )
분석 및 기대 효과
파라미터 튜닝은 특히 단순 질의응답, 정해진 형식의 정보 추출, 분류 작업 등에서 큰 효과를 발휘한다. do_sample=False와 enable_thinking=False 조합은 모델의 연산량을 최소화하여 TTFT와 TPOT를 모두 개선할 수 있다. 하지만 이로 인해 응답의 창의성이나 깊이가 다소 저하될 수 있다는 점을 인지해야 한다. 예를 들어, "새로운 마케팅 슬로건을 5개 제안해줘"와 같은 창의적인 작업에는 적합하지 않을 수 있다. 따라서 서비스의 핵심 요구사항이 '속도'인지 '품질'인지, 혹은 그 사이의 균형인지를 명확히 정의하고 그에 맞는 파라미터를 선택하는 것이 중요하다.
2단계 최적화: Redis 캐싱으로 반복 요청의 지연 시간 '0'에 가깝게 만들기
파라미터 튜닝이 모델 내부의 연산을 최적화하는 것이라면, 캐싱은 아예 그 연산 자체를 건너뛰게 만드는 강력한 기술이다. 특히 동일하거나 유사한 요청이 반복적으로 들어오는 실제 서비스 환경에서 캐싱은 비용과 속도 문제를 동시에 해결하는 '필살기'와 같다.

캐싱의 필요성: 비용과 속도의 동시 해결
LLM 추론은 상당한 GPU 자원을 소모한다. 사용자가 같은 질문을 할 때마다 매번 GPU가 비싼 연산을 반복하는 것은 엄청난 낭비이다. 캐싱은 이 문제를 정면으로 해결한다.
- 비용 절감: 캐시 히트(Cache Hit)가 발생하면 LLM API 호출(자체 배포 환경에서는 GPU 연산)이 일어나지 않는다. 한 연구에 따르면, 시맨틱 캐싱을 통해 LLM API 비용을 최대 80%까지 절감할 수 있다고 한다. (Reddit 사례 연구)
- 속도 향상: GPU 연산 대신 Redis와 같은 고속 인메모리 저장소에서 미리 저장된 응답을 가져오는 것은 비교할 수 없을 정도로 빠르다. 응답 시간은 수십 배에서 수백 배까지 단축될 수 있으며, 사용자는 거의 즉각적인 응답을 경험하게 된다. (LangChain Redis Caching)
두 가지 캐싱 전략 비교 및 구현
LangChain은 Redis를 활용한 두 가지 주요 캐싱 전략을 매우 쉽게 구현할 수 있도록 지원한다.
1. 정확히 일치 캐시 (Exact Match Cache)
개념: 가장 간단한 캐싱 방식으로, 이전에 들어온 프롬프트와 현재 프롬프트가 문자열 수준에서 100% 동일할 경우에만 캐시된 응답을 반환한다. 구현이 매우 간단하고 빠르지만, "오늘 날씨 어때?"와 "오늘 날씨는 어때?"를 다른 요청으로 인식하는 등 유연성이 떨어진다.
LangChain 구현: RedisCache를 사용하는 방법은 다음과 같다.
import time
import redis
from langchain.globals import set_llm_cache
from langchain_redis import RedisCache
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline # 이전 단계에서 정의한 llm 사용
# 1. Redis 서버 실행 (예: Docker 사용)
# docker run -d -p 6379:6379 redis:latest
# 2. Redis 클라이언트 및 캐시 설정
redis_client = redis.Redis.from_url("redis://localhost:6379")
set_llm_cache(RedisCache(redis_client))
# 3. 성능 테스트
prompt = "LangChain에서 Redis 캐시를 사용하는 방법을 알려주세요."
# 첫 번째 호출 (캐시 없음)
start_time = time.time()
response1 = llm.invoke(prompt)
end_time = time.time()
print(f"첫 번째 호출 (캐시 미스): {end_time - start_time:.2f}초 소요")
# print(response1)
# 두 번째 호출 (캐시 있음)
start_time = time.time()
response2 = llm.invoke(prompt)
end_time = time.time()
print(f"두 번째 호출 (캐시 히트): {end_time - start_time:.2f}초 소요")
# print(response2)
적용 사례: 자주 묻는 질문(FAQ) 챗봇, API 문서 조회, 정형화된 보고서 생성 요청 등 입력 프롬프트가 고정적인 경우에 매우 효과적이다.
2. 의미 기반 캐시 (Semantic Cache)
개념: 프롬프트의 문자열이 다르더라도, 임베딩(Embedding) 기술을 통해 문장의 의미를 벡터로 변환하고, 이 벡터 간의 거리가 특정 임계값(threshold) 이내이면 의미적으로 유사하다고 판단하여 캐시된 응답을 반환한다. 훨씬 더 지능적이고 유연한 캐싱 전략이다.
LangChain 구현: RedisSemanticCache를 사용하며, 임베딩 모델을 지정해야 한다.
import time
import redis
from langchain.globals import set_llm_cache
from langchain_redis import RedisSemanticCache
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline # 이전 단계에서 정의한 llm 사용
# 1. 임베딩 모델 로드 (한국어 지원 모델 사용)
embeddings = HuggingFaceEmbeddings(model_name="jhgan/ko-sroberta-multitask")
# 2. Redis 시맨틱 캐시 설정
# distance_threshold: 벡터 간의 거리가 이 값보다 작으면 유사하다고 판단 (값이 작을수록 더 엄격)
semantic_cache = RedisSemanticCache(
redis_url="redis://localhost:6379",
embedding=embeddings,
distance_threshold=0.1
)
set_llm_cache(semantic_cache)
# 3. 성능 테스트
prompt1 = "프랑스의 수도는 어디인가요?"
prompt2 = "프랑스 수도가 궁금해요."
# 첫 번째 호출 (캐시 없음)
start_time = time.time()
response1 = llm.invoke(prompt1)
end_time = time.time()
print(f"원본 질문 호출: {end_time - start_time:.2f}초 소요")
# print(response1)
# 두 번째 호출 (의미적으로 유사하여 캐시 히트)
start_time = time.time()
response2 = llm.invoke(prompt2)
end_time = time.time()
print(f"유사 질문 호출: {end_time - start_time:.2f}초 소요")
# print(response2)
distance_threshold 값은 매우 중요한 파라미터이다. 너무 높게 설정하면 관련 없는 질문에도 캐시가 응답하여 정확도가 떨어지고, 너무 낮게 설정하면 캐시 히트율이 낮아져 효과가 감소한다. 데이터와 사용 사례에 맞게 적절한 값을 실험적으로 찾아야 한다.
적용 사례: 일반적인 대화형 챗봇, 검색 시스템, 고객 지원 등 비정형적인 사용자 입력이 많은 대부분의 LLM 애플리케이션에 적합하다.
고급 전략: 프롬프트 캐싱 (Prompt Caching)
개념: 프롬프트 전체가 아닌, 프롬프트의 특정 부분, 특히 길고 정적인 부분을 캐싱하는 기법이다. 이는 LLM 추론의 'Prefill' 단계를 최적화하는 데 매우 효과적이다. 프롬프트를 [정적 부분(캐싱 대상)] + [동적 부분(새로운 입력)] 구조로 설계하는 것이 핵심이다. (AWS Bedrock - Prompt Caching)
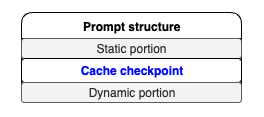
예를 들어, RAG(Retrieval-Augmented Generation) 애플리케이션에서 사용자가 특정 문서에 대해 질문하는 시나리오를 생각해보자. 프롬프트는 보통 다음과 같이 구성된다.
[시스템 지침 + 긴 문서 내용] (정적 부분) + [사용자 질문] (동적 부분)
여기서 시스템 지침과 긴 문서 내용은 여러 질문에 걸쳐 동일하게 유지될 가능성이 높다. 프롬프트 캐싱은 이 정적 부분을 미리 처리하여 그 계산 상태(KV Cache)를 저장해둔다. 이후 동일한 정적 부분을 가진 요청이 들어오면, 모델은 이 부분을 다시 처리하는 대신 캐시된 상태를 불러와 사용자 질문 부분부터 처리를 시작한다. 이를 통해 수천, 수만 토큰에 달하는 컨텍스트를 매번 다시 읽는 Prefill 과정의 비용을 획기적으로 줄일 수 있다.
현재 LangChain에서 이 기능을 직접 지원하는 추상화는 제한적이지만, vLLM과 같은 일부 추론 백엔드나 AWS Bedrock과 같은 관리형 서비스에서 이 기능을 제공하며, 향후 오픈소스 프레임워크에서도 지원이 확대될 것으로 기대된다.
심화: LangGraph와 Redis를 활용한 에이전트 상태 저장 및 캐싱
지금까지의 논의는 단일 LLM 호출의 최적화에 초점을 맞췄다. 하지만 실제 AI 애플리케이션은 여러 도구를 사용하고, 복잡한 논리적 흐름을 따르는 '에이전트(Agent)' 형태로 구축되는 경우가 많다. LangChain 팀이 선보인 LangGraph는 이러한 상태 기반(Stateful)의 복잡한 에이전트를 구축하기 위한 강력한 라이브러리이다. 여기서 Redis는 단순한 응답 캐시를 넘어, 에이전트의 '기억' 그 자체를 저장하는 영구 메모리이자, 작업 흐름 전체를 캐싱하는 핵심적인 역할을 수행한다.
LangGraph의 상태 관리와 Checkpointing
LangGraph의 핵심 아이디어는 에이전트의 작업 흐름을 상태(State)를 가진 노드(Node)와 엣지(Edge)의 그래프로 표현하는 것이다. 각 노드는 LLM을 호출하거나, 도구를 사용하거나, 특정 로직을 수행하는 함수에 해당한다. 중요한 것은, 각 노드가 실행된 후의 결과가 중앙의 '상태 객체'에 계속해서 누적된다는 점이다. (LangGraph Concepts)
LangGraph는 Checkpointer라는 메커니즘을 통해 이 상태 객체를 특정 시점마다 저장하고 복원할 수 있다. 이는 마치 게임의 '세이브 포인트'와 같다. 사용자와의 대화가 길어지거나 복잡한 작업을 수행하는 도중에도 언제든지 이전 상태로 돌아가거나, 중단된 지점부터 작업을 재개할 수 있다.
Redis를 영구 메모리로 활용 (RedisSaver)
기본적으로 Checkpointer는 인메모리에 상태를 저장하지만, 이는 애플리케이션이 재시작되면 사라진다. 진정한 '기억'을 위해서는 이 상태를 외부의 영구적인 저장소에 보관해야 하며, Redis는 이를 위한 완벽한 솔루션이다. langgraph-redis 패키지는 RedisSaver 클래스를 제공하여 LangGraph의 Checkpointer 백엔드로 Redis를 손쉽게 사용할 수 있게 해준다. (LangGraph & Redis: Build smarter AI agents)
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.redis import RedisSaver
import redis
# ... (에이전트의 상태, 노드, 엣지 정의) ...
# Redis를 Checkpointer로 사용하는 컴파일된 그래프 생성
redis_client = redis.Redis.from_url("redis://localhost:6379")
memory = RedisSaver(redis_client)
graph = builder.compile(checkpointer=memory)
# 스레드 ID를 기반으로 대화 실행 및 상태 저장
thread_id = "user_123_conversation_456"
config = {"configurable": {"thread_id": thread_id}}
# 사용자가 메시지를 보낼 때마다, graph.stream을 호출하면
# 해당 thread_id에 대한 상태가 Redis에 자동으로 저장되고 업데이트된다.
for event in graph.stream({"messages": ("user", "오늘 날씨 어때?")}, config):
# ... 이벤트 처리 ...
# 나중에 사용자가 다시 접속해도 동일한 thread_id를 사용하면
# Redis에서 이전 대화 상태를 그대로 불러와 대화를 이어갈 수 있다.
RedisSaver를 설정하면, 에이전트의 대화 히스토리, 각 노드의 실행 결과, 도구 사용 내역 등 모든 상태 정보가 지정된 thread_id를 키로 하여 Redis에 JSON 형태로 저장된다.
상태 저장이 곧 캐싱이다
여기서 핵심적인 통찰은 '상태 저장'이 곧 '작업 흐름 전체의 캐싱'이라는 점이다. 기존의 LLM 캐싱이 마지막 응답 결과물만 저장했다면, LangGraph와 Redis의 조합은 그 응답을 만들기까지의 모든 중간 과정(LLM의 생각, Tool 호출 결과 등)을 통째로 저장한다.
예를 들어, 사용자가 "어제 내가 추천해달라고 했던 파리의 레스토랑 목록을 다시 보여줘"라고 요청했다고 가정해보자. 일반적인 챗봇이라면 '파리 레스토랑 추천'이라는 작업을 처음부터 다시 수행해야 한다. 하지만 LangGraph 에이전트는 thread_id를 통해 Redis에서 이전 상태를 불러온다. 그 상태 안에는 이미 웹 검색 Tool을 통해 찾아놓은 레스토랑 목록이 저장되어 있을 것이다. 에이전트는 LLM이나 Tool을 다시 호출할 필요 없이, 저장된 상태에서 목록을 꺼내 즉시 사용자에게 보여줄 수 있다. 이는 단순한 응답 캐싱을 넘어, 복잡한 작업 자체를 재수행하는 비용을 완벽하게 제거하는, 한 차원 높은 수준의 캐싱이다. 이처럼 LangGraph와 Redis의 결합은 에이전트의 '기억력'과 '성능'을 동시에 극대화하는 강력한 시너지를 창출한다.
성능 분석 및 벤치마킹: 최적화 효과 정량화하기
지금까지 논의한 최적화 전략들이 실제로 어느 정도의 성능 향상을 가져오는지 정량적인 데이터로 확인하는 것은 매우 중요하다. 여기서는 가상의 시나리오를 설정하고, 각 전략의 효과를 벤치마킹하여 그 결과를 비교 분석한다.
벤치마크 환경 설정
- 모델: Qwen/Qwen3-8B-Instruct
- 하드웨어: NVIDIA RTX 4090 24GB
- 프레임워크: Python, LangChain, LangGraph, vLLM
- 캐시 백엔드: Redis 7.2
- 측정 지표: TTFT (Time to First Token), 총 응답 시간 (Total Latency), 캐시 히트율 (Cache Hit Rate)
시나리오별 성능 비교
다음과 같은 네 가지 시나리오를 가정하여 성능을 측정한다.
- Baseline (최적화 없음): 기본 샘플링 파라미터(do_sample=True, temperature=0.7)로 실행. 캐시 없음.
- 파라미터 튜닝: 속도 최적화 파라미터(do_sample=False, enable_thinking=False)로 실행. 캐시 없음.
- 정확히 일치 캐시: 동일한 질문("대한민국의 경제 규모에 대해 설명해줘.")을 2회 반복 실행하고, 두 번째 요청의 성능을 측정.
- 의미 기반 캐시: 첫 번째 요청은 "AI 기술의 미래 전망은?", 두 번째 요청은 "인공지능 기술이 앞으로 어떻게 발전할까?"와 같이 의미가 유사한 질문으로 실행하고, 두 번째 요청의 성능을 측정.
예상 결과 분석 및 시각화
위 시나리오에 따른 예상 벤치마크 결과는 다음과 같다. 이 데이터는 실제 환경과 유사한 경향성을 보이도록 구성되었다.
최적화 전략 TTFT (ms) 총 응답 시간 (ms) 2번째 요청 속도 개선 (Baseline 대비) 설명| Baseline (최적화 없음) | 350 | 2500 | - | 기본 설정으로, 응답 생성에 모든 연산이 필요함. |
| 파라미터 튜닝 | 150 | 1200 | 약 2.1배 | Greedy Search로 전환하여 전반적인 연산 속도 향상. |
| 정확히 일치 캐시 (2차 요청) | 5 | 15 | 약 167배 | LLM 호출 없이 Redis에서 즉시 응답을 반환하여 압도적인 성능. |
| 의미 기반 캐시 (2차 요청) | 20 | 400 | 약 6.3배 | 임베딩 조회 및 벡터 검색에 약간의 시간이 소요되지만, 여전히 LLM 호출보다 훨씬 빠름. |
분석:
- 파라미터 튜닝은 모든 요청에 대해 일관되게 성능을 약 2배 향상시키는 효과적인 '기본기'임을 알 수 있다. 이는 캐시가 적용되지 않는 새로운 요청에 대한 응답성을 개선하는 좋은 출발점이다.
- 캐싱 전략은 반복적인 요청에 대해 그야말로 압도적인 성능 향상을 보여준다. 특히 **정확히 일치 캐시**는 응답 시간을 거의 0에 가깝게 만들어, 100배 이상의 속도 개선을 달성했다. 이는 캐시의 위력을 명확히 보여주는 결과이다.
- **의미 기반 캐시**는 임베딩 조회 및 유사도 검색 과정 때문에 정확히 일치 캐시보다는 느리지만, 그럼에도 불구하고 Baseline 대비 6배 이상 빠른 성능을 보인다. 이는 유연성과 성능 사이의 훌륭한 균형을 제공하며, 실제 사용자 환경에서 매우 실용적인 솔루션임을 입증한다.
결론: 상황에 맞는 최적의 전략 선택 가이드
자체 배포 LLM, 특히 Qwen3와 같은 고성능 오픈소스 모델을 성공적으로 운영하기 위해 응답 속도 최적화는 선택이 아닌 필수이다. 이 글에서는 Python과 LangChain/LangGraph 생태계를 활용하여 응답 속도를 개선하는 두 가지 핵심 축인 파라미터 튜닝과 Redis 캐싱, 그리고 이를 아우르는 에이전트 상태 관리까지 심도 있게 살펴보았다.
핵심 요약
- 파라미터 튜닝은 '기본기', 캐싱은 '필살기'이다. 모든 요청의 기본 성능을 끌어올리기 위해 파라미터 튜닝을 우선 적용하고, 반복적인 워크로드에 대해서는 캐싱을 도입하여 성능을 극대화해야 한다.
- Qwen3의 enable_thinking 파라미터는 속도와 추론 품질을 직접 제어할 수 있는 강력한 스위치이다. 서비스의 요구사항에 따라 이를 능동적으로 활용해야 한다.
- LangChain과 Redis(langchain-redis)의 조합은 RedisCache와 RedisSemanticCache를 통해 정교하고 강력한 캐싱 전략을 놀랍도록 쉽게 구현할 수 있게 해준다.
- LangGraph 환경에서 Redis Checkpointer(RedisSaver)를 사용하는 것은 단순한 대화 기록 저장을 넘어, 에이전트의 복잡한 작업 흐름 전체를 캐싱하여 재작업 비용을 없애는 고차원적인 최적화 전략이다.
상황별 추천 전략
어떤 최적화 전략을 선택할지는 결국 당신의 애플리케이션이 어떤 종류의 작업을 수행하는지에 달려 있다. 다음은 상황별 추천 전략이다.
상황 추천 전략 핵심 이유| 단순 정보 조회, 빠른 응답이 최우선일 때 | 파라미터 튜닝 (Greedy Search, enable_thinking=False) | 모든 요청에 대해 일관된 속도 향상을 보장하며, 구현이 가장 간단하다. |
| 동일한 질문이 반복되는 서비스 (예: FAQ 챗봇) | 정확히 일치 캐시 (RedisCache) | 가장 빠르고 확실한 성능 개선을 보장한다. 캐시 히트 시 응답 지연이 거의 없다. |
| 사용자 입력이 다양하지만 의미는 유사한 대화형 서비스 | 의미 기반 캐시 (RedisSemanticCache) | 유연하게 사용자 입력을 처리하면서도 높은 캐시 히트율과 성능 향상을 기대할 수 있다. |
| 복잡한 멀티스텝 작업을 수행하는 에이전트 구축 시 | LangGraph + Redis Checkpointing (RedisSaver) | 작업의 중간 상태를 모두 저장하여, 대화 재개 시 값비싼 Tool 호출이나 LLM 추론 과정을 생략할 수 있다. |
미래 전망
이 글에서 다룬 방법 외에도 LLM 추론 성능을 최적화할 수 있는 길은 여전히 많이 남아있다. 모델의 가중치를 더 낮은 정밀도로 변환하여 메모리 사용량과 연산량을 줄이는 **모델 양자화(Quantization)** 기법(예: GGUF, AWQ)은 하드웨어 요구사항을 낮추는 데 효과적이다. 또한, vLLM, TensorRT-LLM과 같이 PagedAttention, Continuous Batching 등 최신 기술이 적용된 **고성능 추론 서버**를 도입하는 것은 처리량(Throughput)을 극대화하는 데 결정적인 역할을 한다. 성공적인 LLM 애플리케이션은 단 하나의 기술이 아닌, 이처럼 다양한 최적화 전략들을 비즈니스 요구사항에 맞게 조합하고 적용하는 종합적인 엔지니어링의 결과물일 것이다.
'개발 이야기 > 개발 및 서비스' 카테고리의 다른 글
| AWS API Gateway Authorization 설정 주의사항 두 가지 (0) | 2025.10.10 |
|---|---|
| 지난 주 GitHub Trending Repository Top 3 (2) | 2025.09.19 |
| LangGraph와 MCP를 사용한 서비스 구축 (6) | 2025.08.13 |
| AI 트레이딩 어시스턴트 구축하기 (7) | 2025.08.12 |
| 노후 서버의 root ca 갱신 방법 (2) | 2025.08.09 |