
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- MSSQL
- LLM
- 주식
- 구글
- gemini
- MySQL
- 설정
- Kibana
- error
- 투자
- Windows
- 유니티
- Ai
- nodejs
- 바보
- docker
- FLUTTER
- elasticsearch
- API
- ChatGPT
- app
- AWS
- Python
- JavaScript
- Linux
- JS
- unity
- 분석
- build
- Today
- Total
가끔 보자, 하늘.
2TB x 2개를 RAID로 묶은 4TB SSD 사용하기 본문
elasticsearch를 위한 머신들을 업그레이드 테스트를 위해 조립용 PC에 OS 용 1TB SSD x 1, 데이타 용 2TB SSD x2 를 RAID 0로 묶어 4TB 디스크를 설치하며 기록으로 남길 겸 내용을 정리해 보았습니다. (가끔 여러분도 뭔가 몰라서 검색하다보면 자신이 올린 글이 나올때가 있지 않나요? ^^a)
이 글은 Raid로 묶인 디바이스를 확인, 파티셔닝하여 /data 라는 폴더에 연결하는 것 까지가 목표입니다. 가능한 잡다한 것들은 버리고 흐름을 정리하는데 집중하겠습니다.
그럼 시작해 보겠습니다.
장치 인식 시키기
bios에서 1TB SSD는 Non-raid로 2TB x 2 는 Raid0로 설정 후 os를 설치합니다.
저는 CentOS 7.x minimal 버전을 설치했습니다. 아래 내용은 여러분이 설치하는 OS에 따라 차이가 날 수 있습니다.
df에서는 OS 영역만 현재 보이고 있네요.
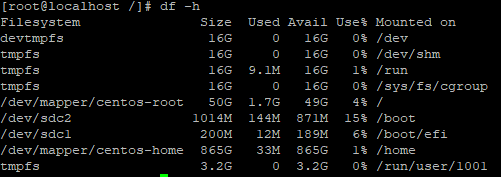
실제 연결된 장치들을 한번 살펴보겠습니다. scsi에 연결된 device 현황을 출력해보니,
boot를 위한 device 1개, 그리고 데이터 저장용으로 사용할 device 두 개, 이렇게 총 3 개의 device가 보이고 있네요.

fdisk로 각 디바이스의 상세 스팩을 확인해 봅니다.
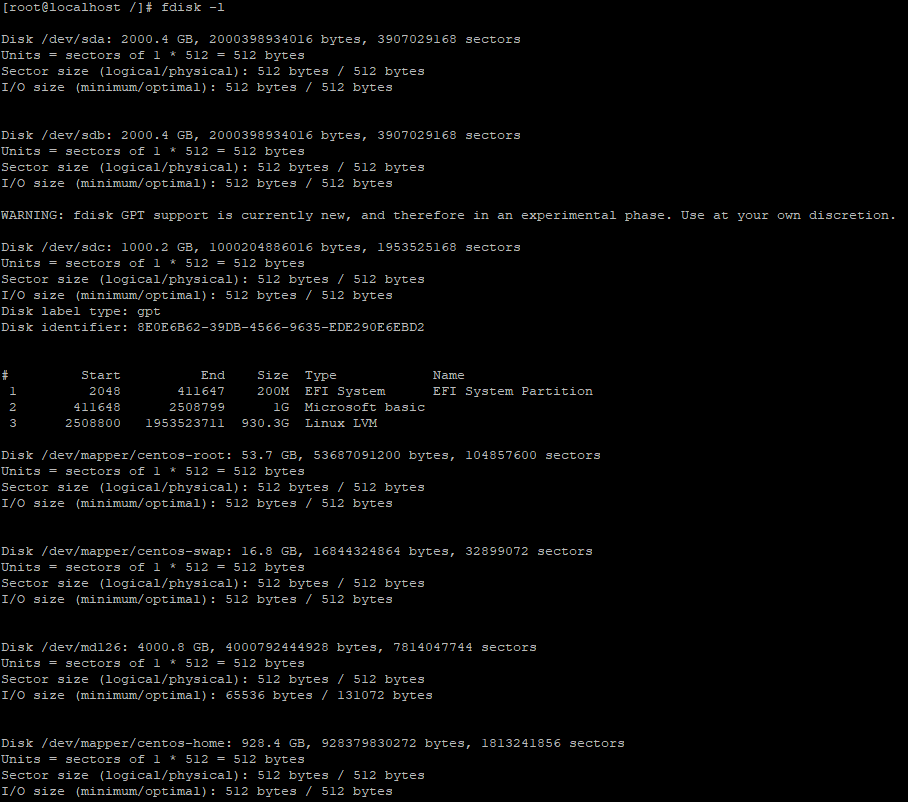
sda/b에 2TB 디스크가, 그리고 sdc에 1TB 디스크가 연결된 것을 확인할 수 있다.
하단 /dev/md126 에는 sba/b 가 raid 0로 묶여있는 것을 확인할 수 있습니다.
레이드에 대한 상세 정보는 /proc/mdstat에서 확인 가능합니다.
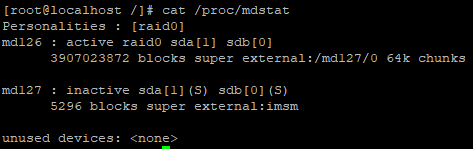
parted -l 로 현재 상태를 검색해보니 아래와 같이 출력됩니다. (나머지 부분은 생략하고 하단의 raid 디바이스에 대해서만 캡쳐했습니다.)

이전에는 raid 구성할 때 mdadm으로 raid 레벨과 구성 장치를 별도로 지정했었는데, 설치할 때 bios의 설정대로 바로 저장장치를 인식해서 설정이 되네요. -0-b
fdisk -l로 sd* 장치들을 상세히 살펴보니 이상한 점이 보입니다.

현재 인식된 장치sda, sdb 가 각각 2TB , sdc가 1TB 입니다. 이 중 OS를 위해 사용되는 sdc는 disk label type이 gpt로 설정되어 있고, raid0로 인식되어 사용중인 sda의 disk label type은 dos로 sdb는 disk label type이 별도 출력이 되어 있지 않습니다.
반면 위에서 봤듯이 raid0로 인식된 md126( sda/sdb로 구성된)의 disk label type은 gpt로 설정되어 있는 것을 볼 수 있습니다. 물리적으로는 2TB용량이니 sda나 sdb가 dos 타입으로 설정되었다 해도 md126에서 gpt로 설정되어, 전체 용량을 사용하는데 문제는 없을 듯 하여, 일단 이 설정 그대로 진행을 했습니다.
이제 파티션을 설정해 보겠습니다.
파티션 설정
이전 시스템까지는 ext4로 설정했지만, 이번 시스템은 용량을 필요에 따라 계속 늘려갈 예정이라 xfs로 설정을 하겠습니다.

(* mkpart의 Start 와 End는 지정하는 파티션의 사용 용량 범위를 지정하는 것이며 숫자만 기록할 경우 MB가 기본이며 %로도 입력할 수 있습니다.)
2TB 초과용량의 저장 디바이스를 사용하기 위해서는 parted 라는 명령을 사용해야 합니다. 비론 2TB 두 개를 사용한 것이지만 총 용량은 4TB이니 parted를 사용해야 합니다.
(* 왜 fdisk가 아닌 parted를 사용하는지, 블록 장치와 파티셔닝에 대한 MBR, GPT 등에 대한 상세 내용은 이 링크로 대체하겠습니다. 필요하신 분만 읽으시면 되지만, 알아두면 더욱 좋습니다. :)
그런데 진행 과정 중에 경고가 하나 있나요? 일단 무시하고 진행해 보겠습니다. 이에 대해서는 이 단원을 마지막에 다시 상세히 다루겠습니다.
file system type을 xfs로 지정했는데 print 해보니 설정이 안되어 있네요??

-f 옵션을 사용해 xfs로 강제로 설정해 보겠습니다. 계속 경고가 포함되어 찜찜함을 지울수가 없네요.
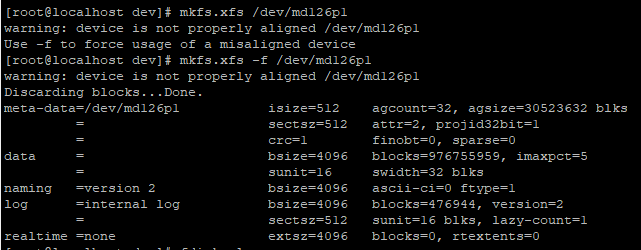
파일 시스템을 설정했지만, 상태를 출력해보니 무슨 경고가 계속 남아 있네요.

"Partition 1 does not start on physical sector boundary." 이 오류는 파티션의 시작이 물리적 섹터의 경계에서 시작되지 않는 것에 대한 경고를 말합니다.
물리적 섹터 바운드리 정보를 살펴봐야겠네요. 참고로 섹터 사이즈는 임의로 저정할 수 없습니다.
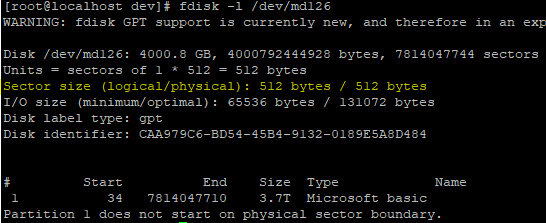
이론적으로 이 이슈는 드라이버의 펌웨어에 따라 read/write 시 io rates에 영향을 미칠 수 있지만 무시해도 큰 문제는 없는 수준입니다. 그래도 ... 이런거 남겨두면 잠자긴 글러먹어서.. -_-;;
전통적으로 start boundary는 1MB로 설정하는게 무난하다. 혹은 저장 장치의 물리적 섹터 바운드리에 맞게 배수로 설정할 수도 있습니다.
일단 이 문제의 시작점을 알아봐야겠네요. parted로 파티셔닝 처리할 때 start 값을 0으로 설정했는데..

성능에 대한 경고가 이미 있었죠. 무시했을 뿐...
다시 mkpart로 파티션 설정을 진행하고 Start값을 1로 지정해보니 경고가 깔끔하게 사라졌네요.

p 옵션으로 살표보면 아래와 같이 출력됩니다.

fdisk로 살펴보니 이전에 있던 경고가 사라진 것도 확인할 수 있습니다.

그럼 mkpart의 Start 값은 무엇을 의미하는 것이었을까? 해당 파티션의 사용 범위를 지정하는 것인데... 0이면 왜 경고가 나오는 걸까요?
저장 장치의 첫 부분은 해당 장치의 기본적인 정보들을 저장합니다. MBR이든 GPT든 저장 장치 관리를 위해 꼭 필요한 영역입니다.
그래서 우리가 단 몇 kB라도 아끼려고 start를 0으로 설정해도 GTP는 자신이 필요한 일부분을 제외하고 저장 장치의 start position을 설정하게 됩니다.
이 할당한 영역이 해당 저장 장치의 units의 배수가 아닌 경우, 이후 저장 위치를 처리하는 과정에서 일부 영역은 unit의 최소 범위보다 적은 문제가 발생하고, 이를 처리하기 위해 os는 추가적인 작업을 처리해야 했기에 위와 같은 경고가 발생하는 것입니다.
아주 미미하지만 그렇다고 무시하기는 찜찜한 그런 거죠.
이제 우리는 Start 의 값으로 1(MB)을 지정했기에 해당 경고는 깔끔하게 사라진 것을 확인할 수 있었다.
위에서 파일 시스템을 xfs로 설정한 것을 기억하시나요? 지금 다시 xfs 설정을 해보시면 경고없이 깔금하게 설정되는 것을 확인 할 수 있습니다. :)

이제 마지막 단계로 넘어가 보겠습니다.
마우트 하기
이제 마운트만 남았네요. 우리가 추가한 4TB 저장 디바이스를 /data로 연결해 보겠습니다.
# mount /dev/md126p1 /data마운트 이후 df로 확인하면 아래와 같이 잘 설정된 것을 확인 할 수 있습니다.

드디어 마무리 되었네요. 사실 AWS EC2 쓰면 기본 설치된 linux에 EBS 용량 필요한거 선택해서 연결하면 끝나는데, 이런 불편한 과정을 거쳐야 하고 필요한 내용은 공부도 해야 하고... 앞으로 더더욱 이런 과정은 없어지겠죠?! (돈이 많다면..)
그래도 회사 입장에서는 유지비용 한푼이라도 아끼려면 이런 삽질은 뭐..
그나저나 이제 전 최신 버전의 elasticsearch 을 설치해 봐야겠네요.
검색 가능한 snapshot 기능이 가장 기대되며 Kibana Lens도 사용자 편의성을 대폭 넓혀줄 것으로 기대하고 있습니다. 두근두근 하네요. :)
'개발 이야기 > 인프라 구축 및 운영' 카테고리의 다른 글
| ES Cluster Nodes Rolling Upgrade 절차 정리 (0) | 2021.02.10 |
|---|---|
| Elasticsearch 7.10 Cluster 설치하기 (0) | 2021.02.09 |
| CentOS7 minimal 버전 설치부터 원격 접속까지.. (0) | 2021.01.21 |
| AWS S3 API 사용을 위한 권한 설정 관련 (0) | 2020.12.22 |
| EBS Volume 확장하기 (0) | 2020.09.08 |
