
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 분석
- API
- 유니티
- JS
- docker
- ChatGPT
- elasticsearch
- 주식
- error
- JavaScript
- Windows
- FLUTTER
- Ai
- nodejs
- app
- AWS
- MSSQL
- LLM
- Python
- Kibana
- 바보
- 설정
- MySQL
- 구글
- build
- 투자
- Linux
- unity
- gemini
- Today
- Total
가끔 보자, 하늘.
Chat with RTX 사용기 본문
24년 다닌 회사를 곧 퇴사!! 열심히 다녔는데 인계할 내용이 많지는 않네.
게임 개발회사라 지금 내가 하는 인하우스툴 및 서비스, 데이터 엔지니어링 업무를 받을 사람은 없지만 그래도 인수인계는 해야 해서 현재의 동료들에게 전달해야만 하는 상황이다.
비용 아끼려도 남아 있는 시스템으로 구축된 거라 누군가 이 업무를 해야 한다면 외부에 잘 만들어둔 서비스를 쓰라고 강조에 강조를 한다. 하지만.. 우리는 좋... 하여간..
현재 동료 중 이걸 인수인계할 수 있는 인원들이 없는데다 새로 뽑을 계획이 없는 상황.
그래서 나를 대신해 줄 sLLM이 반드시 필요한 상황이었다. 하지만 이쪽 분야에 대해서는 실무를 해본적이 없기 때문에 구글구글구글링링링..
참고 자료
- https://www.youtube.com/watch?v=4I9AUFuBlFs
- https://github.com/choijhyeok/easy_finetuner
- https://github.com/lxe/simple-llm-finetuner
- https://github.com/jina-ai/finetuner
평소에 AIFactory에서 진행하는 온라인 세미나를 가끔 보던 터라 easy_finetuner와 llama2 를 베이스로 내 문서들을 학습한 LoRA를 만들어 적용해야 겠다고 결정을 했다. https://github.com/blackwitch/easy_finetuner 에 fork해서 데이터 셋 만들기부터 학습 결과까지 한번에 처리할 수 있게 기능을 추가하여(계속 기능 추가 중. 학습 데이터를 자동으로 개수를 늘리는 기능, 학습 데이터를 기준으로 검증 데이터를 자동으로 만들어 연동하는 기능과 최종 결과물의 학습 결과를 검증하는 기능을 추가할 예정) 개발 중이었다.
겨우 UI 좀 수정하고 결과가 좀 나오네?? 하는 사이 두둥!!! NVIDIA Chat with RTX가 발표!!! 어 !!!????
당장 다운로드...!!! 31GB에 설치 중에 다운로드 포함해서 총 8시간 걸림... 다음날... !!
인수인계를 위한 문서를 모아서 하나의 폴더에 넣고 Chat with rtx에서 지정하니 지가 필요한 데이터를 만든다. 0_first 라는 폴더를 지정했다면 0_first_vector_embedding 폴더를 만들고 거기에 Chat에 쓸 데이터를 생성했다.
지원하는 AI Model은 Mistral 7B int4와 Llama2 13B int4. 데이터는 faiss(https://faiss.ai/) 를 이용해 로컬에 vector db와 몇 개의 metadata를 생성했다.
문서 파일들 용량이 1.34MB인데 0.98MB의 데이터를 만들었다. 한 번 빌드한 폴더를 다시 지정할 때는 변경된 문서 여부 체크만 한다. 일부 변경된 파일에 대해서만 갱신하므로 빠르게 작업 가능한 듯.
드디어 테스트!! 두둥!!! 한글로 물어보면 깔끔하게 영어로 답변해주네.
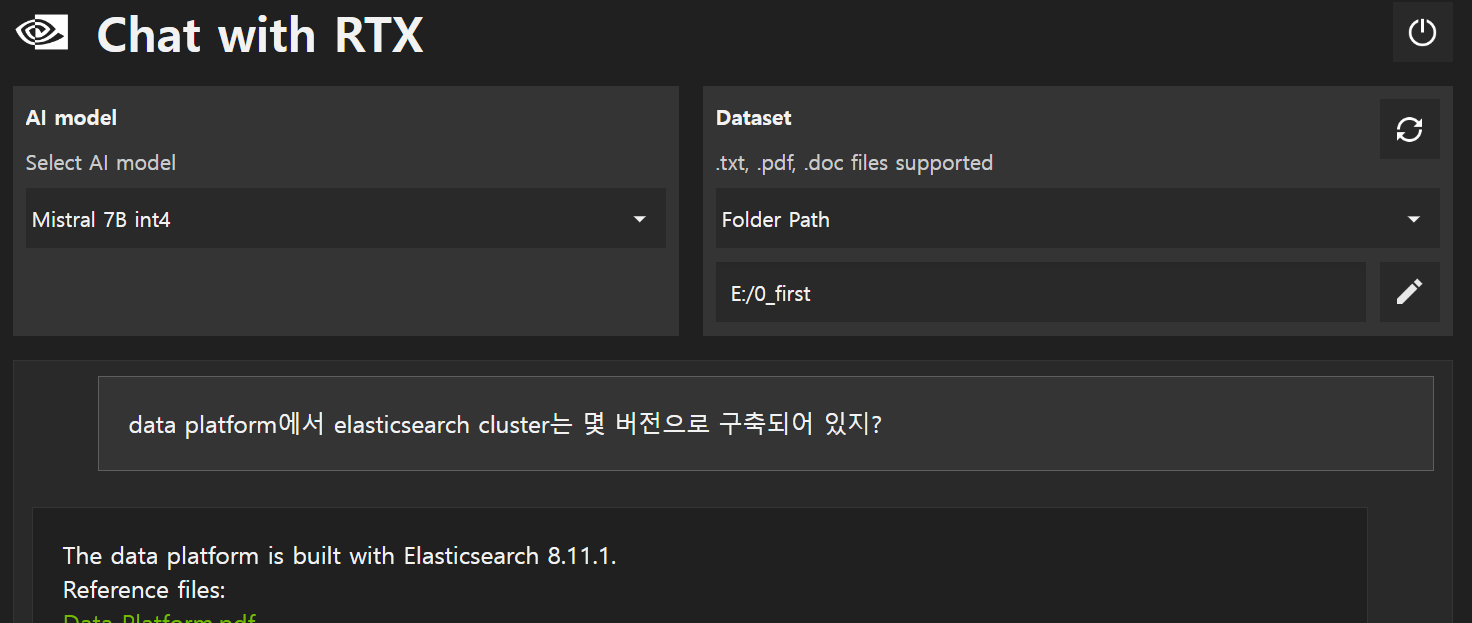
그리고 참고한 문서를 링크해줘서 클릭하면 바로 문서를 볼 수 있다. 역시 아직은 버전은 0.2라 그런지 문제는 있네.
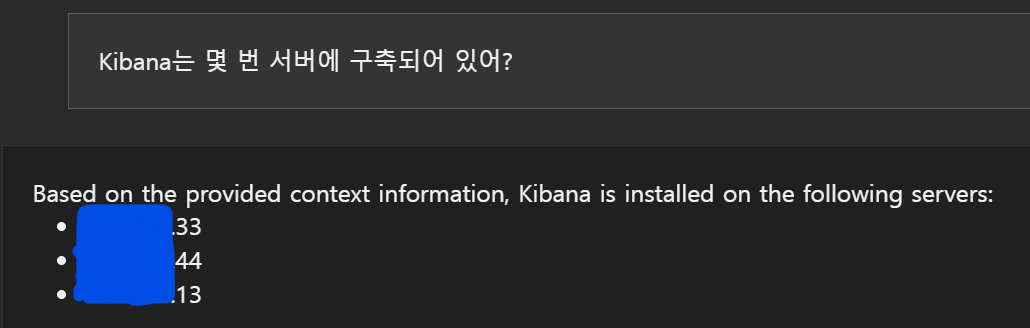
Hallucination이 당연히 존재함. 33번에만 설치되어 있지만 44번과 13번에도 설치되어 있다고 나옴. 어디서 저런 정보를 찾은거지? 심지어 13번이라는 ip는 없는데 -_-a
똑같은 질문에 비슷한 답변을 내는 경우 응답속도는 llama2 7b와 LoRA, langchain API를 이용한 것보다 조금 빠른 느낌.
모델은 Mistral 7B int4이나 Llama2 13B int4나 결과가 비슷한데 Mistral이 속도면에서 빨라 더 좋은 듯.
직접 만든건 답변을 완성 후 출력하고 Chat with RTX는 스트리밍으로 답변을 출력하기 때문에 끝나는 시간을 기준으로 보면 Chat with RTX가 최소 40% 이상은 빠른 듯. (TEST PC : RTX 4080 / 16GB)
저장된 Vector DB에서 관련 문서를 검색하고 LLM으로 검색된 텍스트를 전달해 다듬어 출력하는 듯. (이전에 PDF 문서 검색툴을 이와 비슷하게 만든 적이 있음. 아마도 그런 구조가 아닐까 생각된다.)
결론은 있는 문서 검색용으로는 LoRA 학습 시키는 것보다 이게 더 좋은 듯. 더 비용효율적이다. LLM 학습 관련해서 별도로 공부할 필요도 없고 특히 학습에 사용할 데이터를 만들 필요도 없다. 게다가 여러 포멧의 문서를 지원한다. PDF, DOC, TXT 등등.
앞으로 퇴사하는 사람들 전화 받기 싫으면 문서 잘 정리해서 이거 연동해주면 전화 좀 덜 받을 듯. :)
'개발 이야기 > DB, 데이터분석, AI' 카테고리의 다른 글
| Google Analytics 연동 절차 (0) | 2026.02.19 |
|---|---|
| DATABASE 1~3정규화를 가장 쉽게 이해하기 (0) | 2024.07.20 |
| 수식없이 LLM 이해하기 (32) | 2024.02.15 |
| Elasticsearch 에서 특정 날짜 데이터 재구축이 필요할 때 (32) | 2023.12.27 |
| MySQL/MariaDB에 TLS 적용하기 (1) | 2023.12.08 |

