
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- elasticsearch
- LLM
- 분석
- MySQL
- 유니티
- 주식
- gemini
- Kibana
- 구글
- JavaScript
- build
- MSSQL
- app
- FLUTTER
- ChatGPT
- nodejs
- Python
- 설정
- 바보
- 투자
- Linux
- Ai
- docker
- AWS
- unity
- JS
- Windows
- API
- error
- Today
- Total
가끔 보자, 하늘.
AWS Glue, Athen, Quicksight 첫 사용기 본문
Data pipeline 을 AWS로 마이그레이션 하려고 관련 제품들을 살펴보는 중입니다. 기존 프로세스를 어떻게 AWS로 가져올지를 검토하기 위해 알아볼 겸 간단히 정리해 보겠습니다.
현재는 각종 서비스의 데이터를 가져오기 위해 시기에 따라 제작하여 운영해오고 있었기 때문에 서비스 별로 서로 다른 pipeline을 사용하고 있습니다.
예를들어 데이터 수집을 위한 (1) 전용 api server를 만들고, (2) 데이터 손실 방지를 위해 redis에 일정 기간 저장/백업 후 자동 삭제, (3) 이를 logstash로 정기적으로 가져와 (4) Elasticsearch에 저장, 다시 이를 (5) DW에 가공하여 저장, 일부는 실시간 지표 확인을 위해 (6) S3에 저장, 모바일/웹에서 (7) 뷰어를 제공해 S3의 실시간 지표 확인!!! 이런 절차로 최종 데이터가 전달되었습니다. 적고나니 더 복잡하네요.
일부 서비스는 별도 가공 절차를 제공하기도 했기 때문에 이 내용보다 실제로 더 복잡합니다. 대신 비용은 PC 몇 대로 가능했고 하루 10GB 데이터 정도는 문제없이 처리했기 때문에 당장 큰 문제가 있는 건 아니었습니다. 하지만 앞으로 제공할 서비스들이 늘어날 계획이고 관리 비용을 줄이기 위해 AWS의 서비스들을 이용해 통합하려 준비하는 과정에 있습니다.
(A)Kinesis Data stream과 firehose를 통해 S3에 저장된 데이터를 (B)Glue, Athena, Quicksight를 이용해 시각화 하는 과정을 간단히 정리해 보았습니다. 다음에는(C)이런 과정을 자동화하고 불필요한 데이터를 자동으로 정리해 비용을 절감하는 방법, 그리고 (D)자체 서비스를 위해 데이터를 어떻게 사용해야 하는 과정 까지 순서대로 정리해 볼 예정입니다.
(A)번 과정은 글로 정리해둘 만큼 복잡한 내용이 아니라 따로 정리하지는 않습니다. 혹시 필요하신 분은 댓글 달아 주시면 추가로 올려두겠습니다.
혹시 이전에 이런 프로세스를 구축해보신 분이 있다면 제가 정리한 A -> B -> C -> D의 과정 중 불필요하거나 비용을 더 절감하면서 운영할 수 있는 노하우가 있다면 공유 부탁드립니다.
--------------------------------------------------------------------------------------------------------------------------------------------------------------
어떤 방식으로든 수집된 데이터가 S3에 json 형태로 저장되어 있다고 가정하겠습니다.
우선 AWS Glue console에서 에서 사용할 역할을 생성합니다. (AWS Resource 접근 시 사용할 권한 부여)
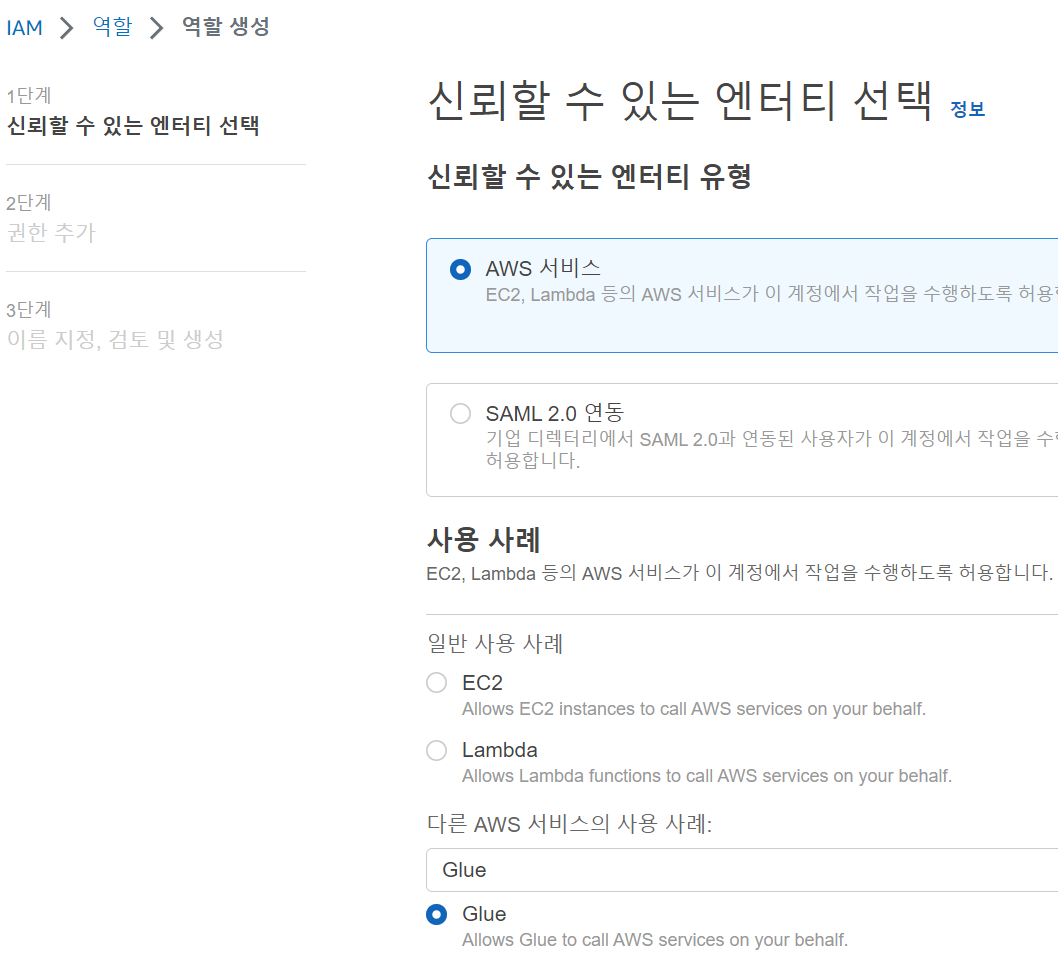
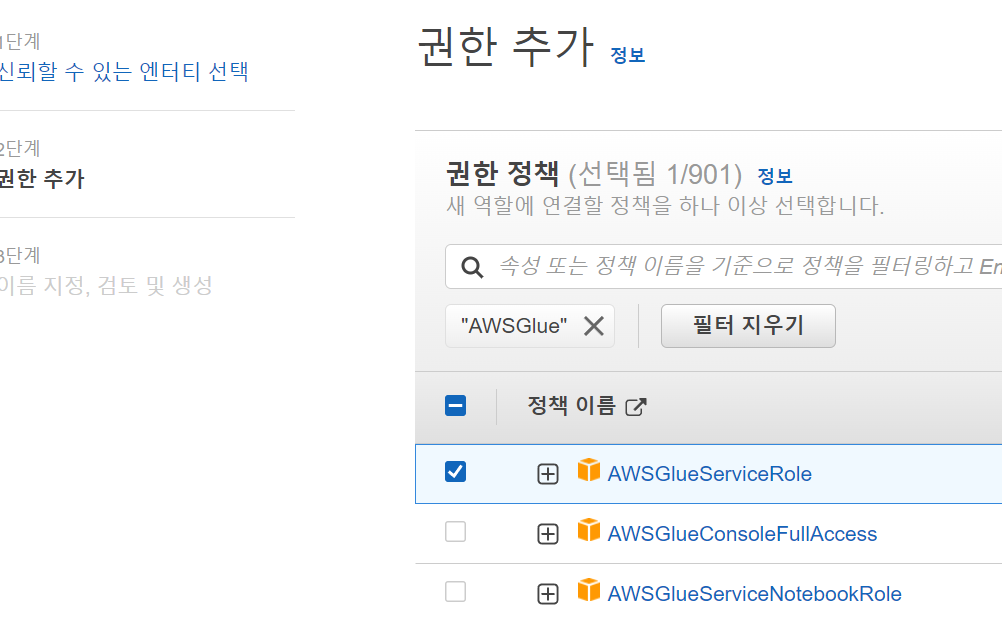
이후 RoleForGlue라는 이름으로 저장, 다시 AWS Glue Console에서 생성한 role을 선택합니다.

이후 사용자를 생성합니다. 여기서는 "UserForGlue"라는 이름으로 사용자도 생성합니다.
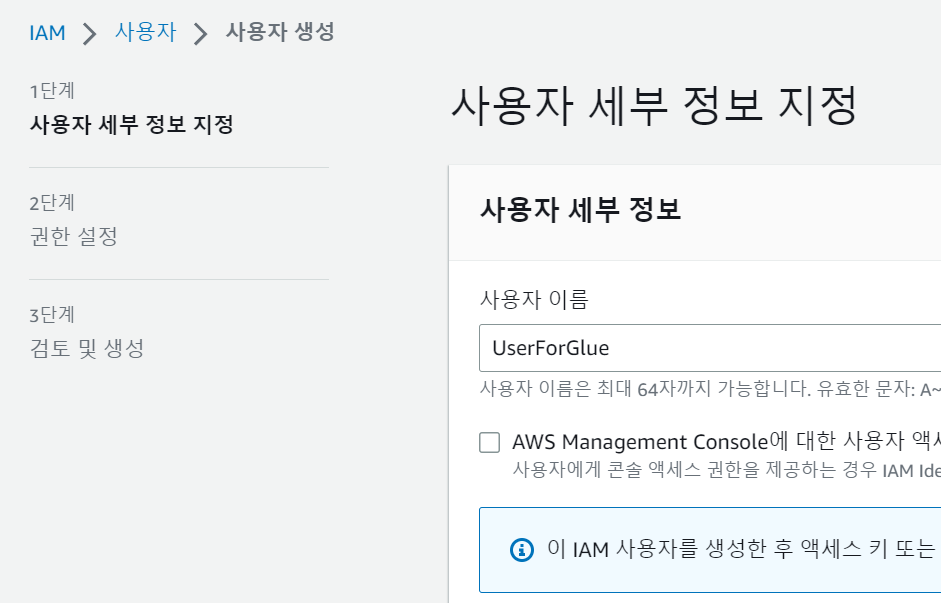
권한 설정에서는 AWSGlueConsoleFullAccess를 선택합니다. (상세 내용은 이 링크를 참고하세요.)
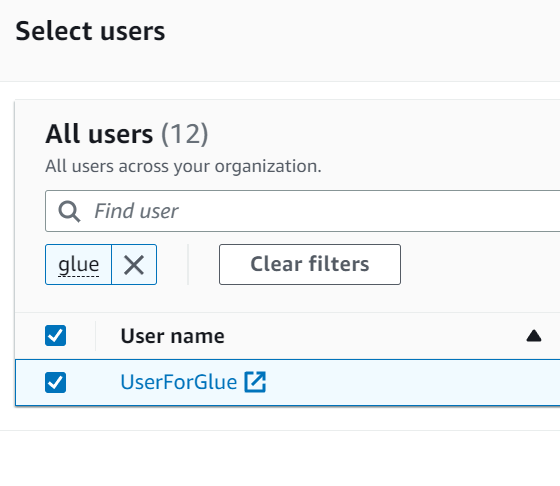
다음은 S3 접근 권한을 설정합니다.

이제 필요한 기본 설정은 끝났습니다. 다음으로 Crawlers를 이용해 S3의 데이터를 import 해 보겠습니다.
source가 있는 S3를 지정합니다.

그리고 사용할 IAM Role을 선택합니다. 좀전에 생성했던 RoleForGlue를 선택하겠습니다.

crwaling된 데이터를 저장할 DB를 선택합니다.

기존에 생성된 DB가 없으니 "Add database"를 눌러 DB 명을 입력하여 새로 생성합니다.
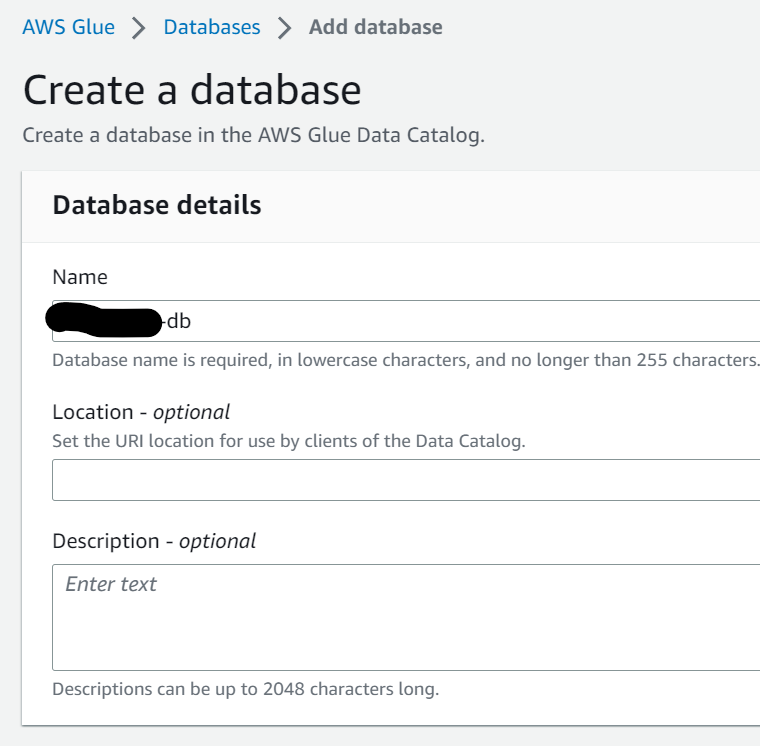
Crawler schedule에서는 작업을 실행할 시간 간격을 선택할 수 있는데, 여기서는 일단 "On demand"를 선택해 우리가 필요할 때 crawling되도록 하겠습니다.
crawler를 생성했다면 실제로 실행해서 데이터를 가져오도록 합니다.

작업이 완료되면 "Data Catalog"의 Databases 에서 생성된 DB를 확인할 수 있으며 Schema도 json format에 맞춰서 잘 정리된 모습을 볼 수 있습니다.

상세 데이터를 보려면 위 스샷 화면의 우측 상단에 "Actions" 를 클릭하고 "View data"를 선택하면 Athena 화면으로 전환 후 실제 데이터를 확인할 수 있습니다.
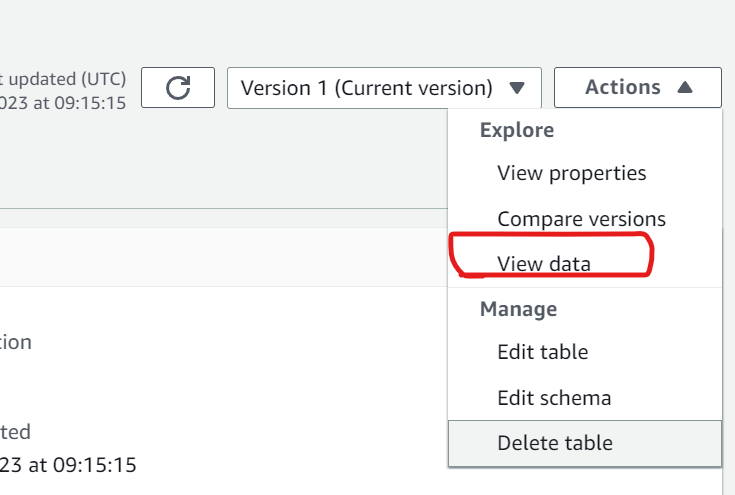
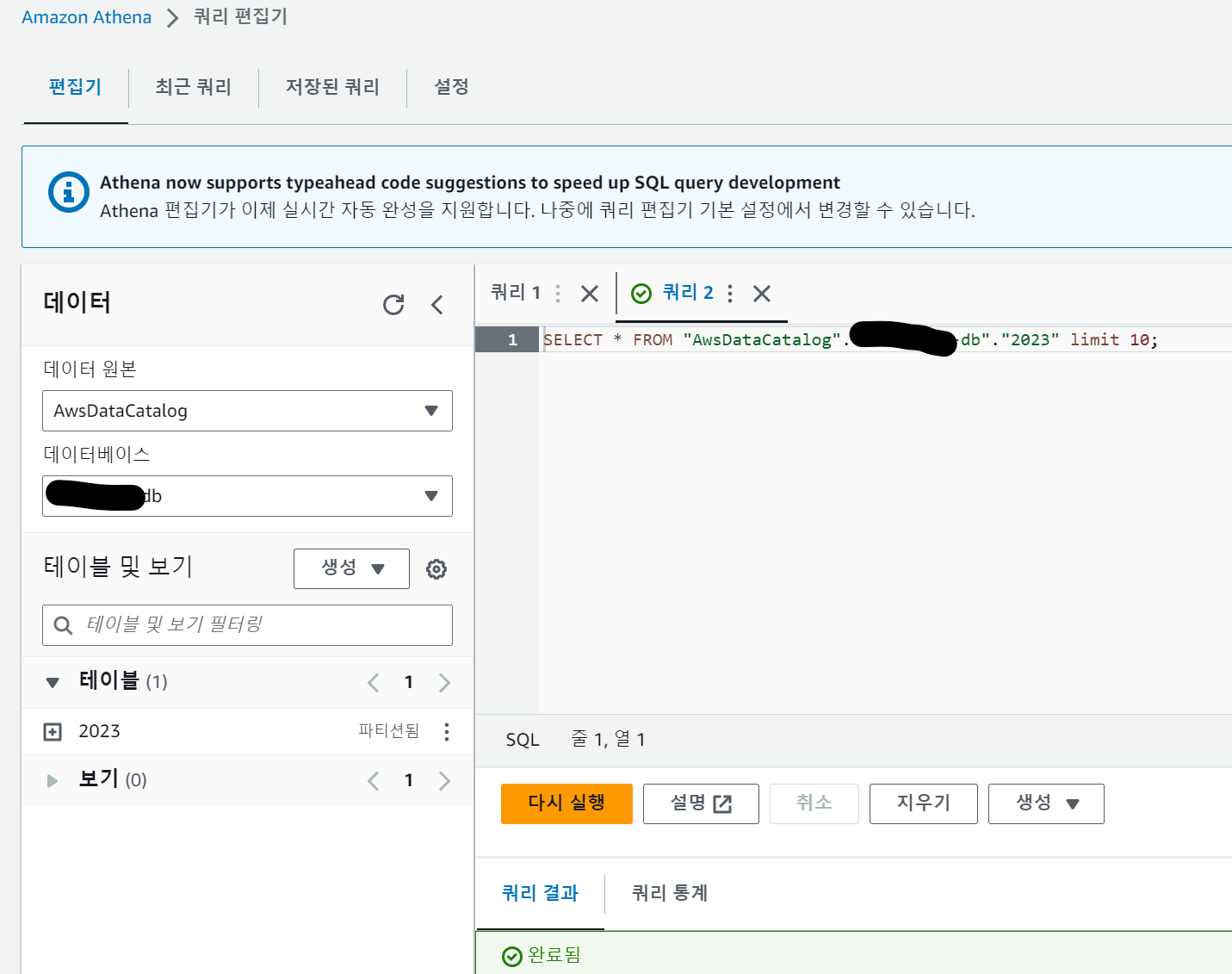
SQL을 이용해 쿼리도 할 수 있습니다.
마지막으로 이 데이터를 Quicksight를 통해 시각화해 보겠습니다. QuickSight에서 "Datasets" 메뉴로 가서 우측 상단의 "New datasets" 버튼을 클릭합니다. 그리고 Athena를 선택, Data Source Name 을 입력하고 "Create data source" 버튼을 선택합니다.

그러면 Glue에서 생성했던 테이블을 선택하는 화면이 나옵니다. 원하는 테이블을 선택합니다.
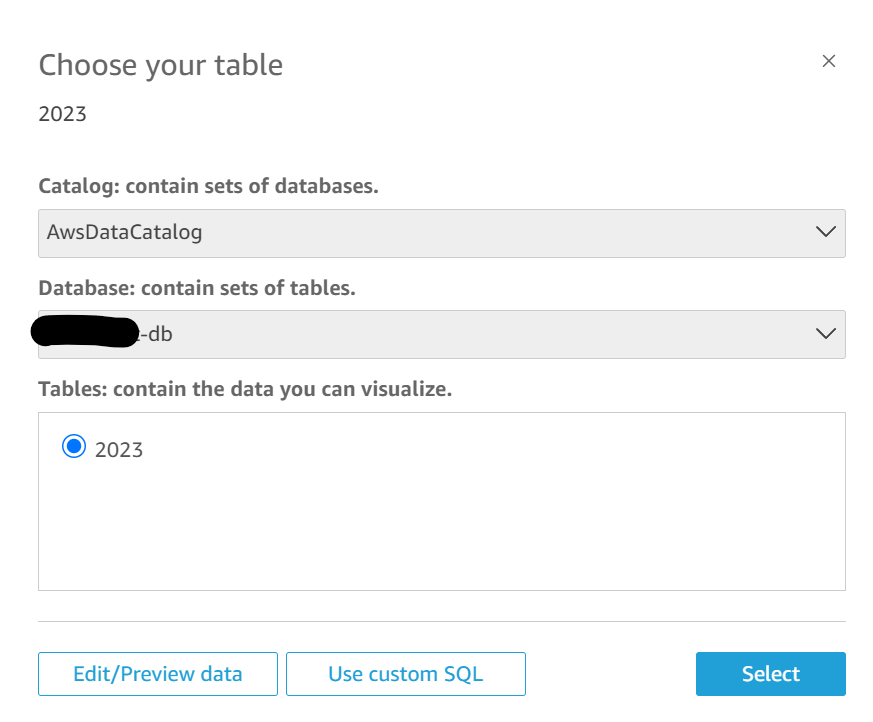
Dataset을 만들기전에 Edit/Preview data를 통해 가져올 데이터를 편집-컬럼명 변경, 타입 변경- 하거나 filter를 사용해 필요한 데이터만 정제하여 가져올 수 있습니다.

Database를 생성하지 않고 기존 데이터에 추가를 할 수도 있습니다.

새롭게 생성할 때 별도 저장공간인 SPICE로 import 하거나 별도 저장하지 않고 바로 데이터를 쿼리하여 결과물을 만든 후 버릴 수도 있습니다.

이 예제에서는 SPICE에 저장 후 시각화 합니다.
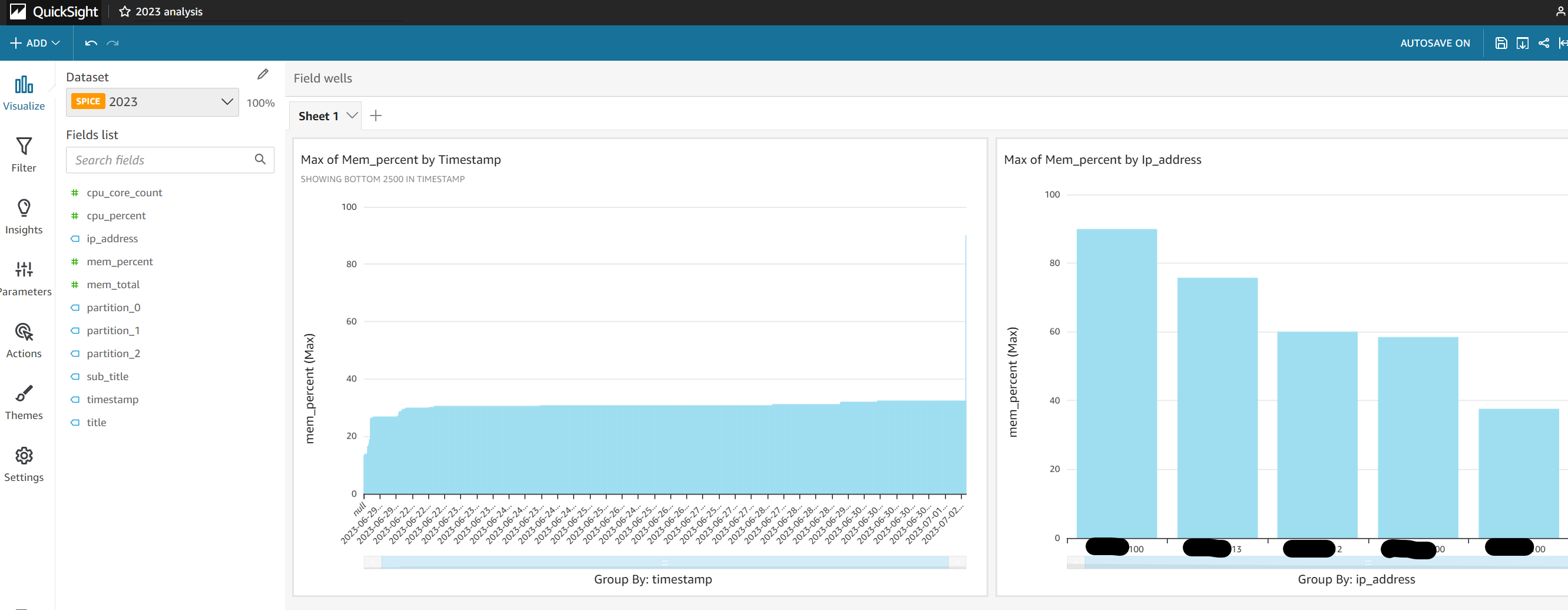
이렇게 완성된 시각화 자료를 외부로 손쉽게 공유할 수 있습니다. 우측 상단의 공유 아이콘을 클릭하고 "Publish a dashboard"를 선택합니다.

dashboard를 생성했다면 dashboard 화면 우측 상단의 공유 버튼을 다시 누릅니다.
그리고 "publish this view"를 선택하면 link가 생성되는데 이는 quicksight 계정을 가진 사람만 볼 수 있는 링크입니다.
그리고 "public dashboard"를 선택하면 아래와 같은 화면을 볼 수 있습니다.

여기서 결과물을 공유할 수 있는 다양한 방법을 선택할 수 있습니다. embed code를 사용하면 손쉽게 별도 사이트에 적용할 수 있을 듯 한데 이 결과를 추후 별도로 정리해서 공유하겠습니다.
이상 간단히 세 제품을 이용해 data import 부터 시각화까지 알아보았습니다. 사용하시려는 분들에게 도움이 되셨기를... ^^
'개발 이야기 > DB, 데이터분석, AI' 카테고리의 다른 글
| Elasticsearch 저장 용량 이슈 (0) | 2023.08.16 |
|---|---|
| mssql transaction log 파일 강제 삭제 (0) | 2023.07.27 |
| LLM 작동방식 및 용어 알아보기 (0) | 2023.05.15 |
| MSSQL DB의 계정이 db_owner로 지정되어 삭제되지 않을 경우 (0) | 2022.12.09 |
| MySQL DB 바이너리 로그 삭제 처리 (0) | 2022.10.17 |
