
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- MSSQL
- Ai
- 설정
- elasticsearch
- Python
- Kibana
- mariadb
- MySQL
- docker
- JS
- ChatGPT
- nodejs
- sample
- 구글
- Windows
- SSL
- AWS
- s3
- ssh
- unity
- 유니티
- API
- React
- JavaScript
- Linux
- 영어
- error
- build
- logstash
- Today
- Total
가끔 보자, 하늘.
mariadb(mysql) 이중화 구성 본문
이전에 클러스터 구축에 대한 내용을 정리했는데, 오늘은 이중화 구성을 정리해 보겠습니다.
클러스터로 구성하는게 이중화 구성 보다는 많은 장점이 있다고 생각하지만 쓰임새에 따라 필요한 경우도 있어서 정리를 해봤습니다.
이중화를 구성하는 여러 방법들이 있지만 여기서는 가장 심플한 구성의 이중화를 정리해 보겠습니다.
지금부터 master db를 M, slave db를 S라고 지칭하겠습니다.
Replication 절차

mariadb(mysql)은 이중화 과정을 살펴보면 M에 event가 발생하면 M은 S와 복제를 위해 생성해둔 binary log file에 DB업데이트와 동시에 기록을 해둡니다. 그리고 S는 자신이 M의 binary log 몇 번째 위치의 데이터를 마지막으로 가져왔는지 기록했다가 M의 binary log에 새로운 기록이 업데이트 되면 가져오고 가져온 위치를 기억해 둡니다.
이후 S는 전달된 binary log를 relay log에 기록 후 이를 순차적으로 자신의 db에 기록하게 됩니다.
Master DB 설정
M의 /etc/my.cnf.d/server.cnf에 아래와 같은 내용을 추가합니다.
[mysqld]
log-bin=mysql-bin
server-id=1log-bin은 binary log로 사용할 파일명입니다.
그리고 S에서 M에 접근하는데 사용하는 계정을 생성합니다.
mysql> grant replication slave on *.* to 'repluser'@'%' identified by 'password';S가 접근할 때 사용할 계정을 repluser로 설정했습니다.
replication 시작 시점 이전의 정보들을 자동으로 복제 시키지 않기 때문에 복제에 필요한 데이터들은 수동으로 옮겨줘야 합니다.
(*사전 복제할 데이터가 없는 상태라면 아래 과정을 건너띄세요.)
기존 database들을 mysqldump로 slave에 전달해야 합니다.
M에서 아래와 같이 덤프 파일을 생성합니다.
mysqldump -u username -p --all-databases > dump.sql가능하다면 DB에 업데이트가 일어나지 않도록 조치 후 dump를 하시는게 좋습니다.
이제 M에서 필요한 모든 준비 작업을 마쳤습니다. M의 mariadb 데몬을 재시작하세요.
그리고 show master status\G 로 확인하면 아래와 같은 결과를 확인할 수 있습니다.

binlog_do_db와 binlog_ignore_db는 특정 DB만 replication 하거나 특정 DB만 replication에서 제외하도록 할 때 해당 DB가 무엇인지 확인할 수 있는 내용이지만, 이 예제에서는 전체 DB를 replication 하도록 설정했으므로 비어 있습니다.
Slave DB 설정
다음으로 S의 설정을 진행합니다.
우선 생성한 덤프 파일을 가져옵니다. scp를 이용해 M에서 생성된 dump 파일을 복사합니다.
scp username@M_ip_address:/dump.sql_file_full_path ./그리고 S에 복구합니다. (혹시 이전에 slave가 시작된 상태라면 stop slave로 복제를 멈춰주세요.)
mysql -u user -p < dump.sql
이제 S의 /etc/my.cnf.d/server.cnf를 설정합니다. M의 복제할 binary log 파일명과 포지션을 설정할 수 있지만, 초기 상태라면 굳이 지정할 필요없습니다.
[mysqld]
server-id=2그리고 M에 접속할 정보를 설정합니다.
mysql> change master to master_host = 'M_ip_address', master_user='repluser', master_password='password';이제 S 를 재시작 합니다. 그리고 slave를 시작합니다.
mysql> start slave;이제 복제에 필요한 모든 절차가 마무리 되었습니다.
show slave status\G; 로 상태를 확인하시면 다음과 같은 결과를 확인할 수 있습니다.
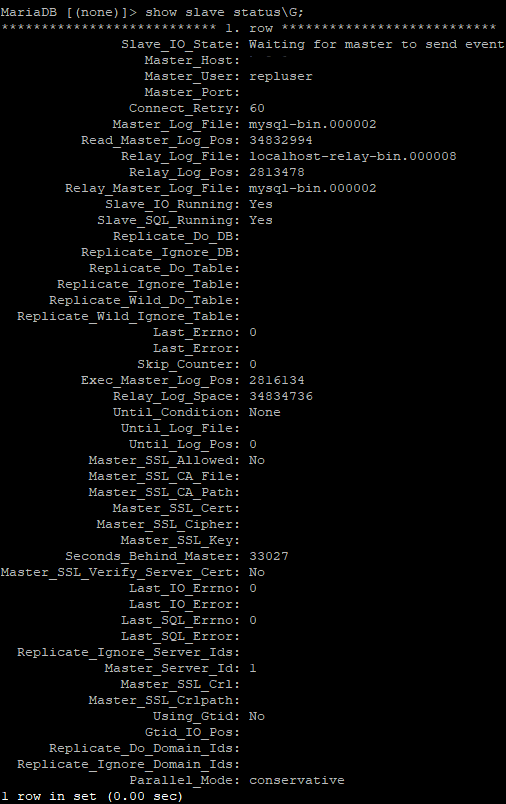
문제 발생 시 해결 방법
모든 과정이 순조로웠기를 바랍니다. 하지만 언제 어디서나 문제가 발생할 수 있고, 기존에 문제가 발생했으니 이 글을 보는 걸 수도 있겠죠.
일단 문제가 발생했다면 S에서 show slave status\G 로 상태를 확인해 보세요.
여러 상태 값 중 Slave_IO_Running 과 Slave_SQL_Running, 그리고 Last_Errno, Last_Error 로 상태를 확인할 수 있습니다.
Slave_IO_Running 이 No라면 복제를 진행하지 않고 있는 경우이며 이는 start slave 하시면 됩니다.
Slave_SQL_Running이 No라면 복제를 시작했지만 어떤 이유로 복제 절차를 멈춘 상태입니다.
이때는 Last_Errno와 Last_Error를 확인해 보세요.
[각 에러 별 해결 방법]
| Last_Errno | 해결 방법 |
| 1032 | HA_ERR_KEY_NOT_FOUND. master에서 delete from tableA where key=1; 이란 이벤트가 발생했는데, slave tableA에 key=1인 데이터가 없을 때 발생할 수 있습니다. 에러 메세지에서 어떤 테이블의 데이터에 문제가 발생했는지 볼 수 있다면 slave db에서 해당 이슈가 발생하지 않도록 수정 후 진행하시면 됩니다. (binlog를 볼 수 있는 별도 툴을 이용하셔서 살펴 볼 수 있습니다.) 만약 정확한 원인을 알 수 없다면 skip할 수도 있지만 master, slave를 서비스 정지 후 정확히 복제하고 진행하시는게 최선입니다. |
| 1062 | Error 'Duplicatte entry'. 특정 테이블의 primary key 값이 중복된 경우 발생합니다. slave측에서 insert 되거나 master-master 구조에서 발생할 수 있습니다. master-slave 구조라면 slave측에서 insert 되지 않도록 조치 후 중복된 키의 데이터를 삭제 후 다시 복제를 진행하세요. master-master 구조에서도 키가 중복되지 않도록 해야 하는데 만약 auto increasement 옵션이 있는 경우 시작값를 1, 2로 각각 다르게 하고 2씩 증가시키도록 조정하세요. |
| 1146 | Error 'Table doesn't exist'. 특정 테이블이 존재하지 않을 때 발생합니다. master db에 존재하는 table이 slave db에 존재하지 않는 문제로, 복제 전에 master, slave간 db가 맞춰지지 않았거나 테이블 생성 퀄리가 다른 이유로 스킵된 경우 발생합니다. 해당 테이블만 문제가 발생한 query 실행 전 상태로 dump해서 slave로 넣을 수 있으면 좋겠지만 사실 어렵습니다. 해당 table의 정보에 따라 어떻게 처리할지 달라지겠지만 master db의 table을 dump해서 slave에 넣은 후 에러가 발생할 때마다 수동으로 스킵하는 방법을 추천드립니다. |
| 2003 | Error connecting to master. S에서 M에 접근할 때 사용하는 계정 정보 혹은 M의 정보 설정이 잘못된 경우 발생합니다. 위 내용에서 해당 설정 과정에 문제가 없었는지 다시 살펴보세요. |
[에러 발생 후 정상화 절차]
config 파일에서 특정 에러를 skip 할 수 있지만 추천드리지 않습니다. 가능한 문제의 원인을 파악하여 해결해야 합니다.
에러의 원인을 해결했다면 slave를 재시작(stop slave; start slave;) 하신 후 status를 확인(show slave status\G;)하여 Slave_SQL_Running이 Yes인 상태로 전환되었는지, Last_Errno가 0인지 확인하시면 됩니다.
만약 여전히 같은 상황인 경우, 실행해야 할 마지막 query가 어떤 이유로 처리가 되지 않는 경우가 있을 수 있습니다.
이런 경우 복제를 잠시 중지 후 (stop slave;) 에러가 발생한 쿼리 하나를 일시적으로 스킵할 수 있습니다.( set global sql_slave_skip_counter=1; => 1 이상의 값을 지정할 수 있습니다. ) 그리고 다시 복제를 시작하세요.(start slave;)
[복제 지연 문제]
특별히 에러가 발생하는건 아니지만 복제가 상당히 느린 경우가 발생할 수 있습니다. 백업 용도만으로 사용할 때는 몇 분 지연이 큰 문제는 아니지만 부하분산을 위해 slave를 select용으로 사용한다면 작은 지연도 큰 문제가 될 수 있습니다.
오랜 시간 지연이 발생하는 query가 있다면 가능한 최적화 할 필요가 있겠지만, 꼭 필요해서 쓴 경우라면 어쩔 수 없겠죠.
혹은 lock에 의한 지연도 발생할 수 있습니다. show processlist; 로 진행중인 쿼리를 확인 후 state에 lock으로 인해 대기중인 프로세스를 확인하여 원인 해결 혹은 일시적인 문제라면 kill 하시면 됩니다.
work load 증가로 인한 지연도 종종 발생합니다. master에서 query가 증가하는데 slave가 single thread로 처리한다면 지연이 발생할 수 있습니다.
mariadb는 10.0.5 버전부터, mysql은 5.6.3 버전부터 병렬복제를 지원합니다.
mysql은 slave_parallel_workers로, mariadb는 slave_parallel_threads로 수정이 가능합니다.
global variable 수정 시에는 복제를 멈춘 후 수정해야 합니다.
mysql> stop slave;
Query OK, 0 rows affected (0.00 sec)
mysql> set global slave_parallel_threads=2; >> mariadb
mysql> set global slave_parallel_workers=2; >> mysql
Query OK, 0 rows affected (0.00 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
그 외 다양한 이슈들이 있겠지만 여기서는 구성에 초점을 맞춘 글이라 대표적인 것들만 정리했습니다.
그럼 이만... 모두 좋은 하루 되시길 바랍니다. :)
'개발 이야기 > 인프라 구축 및 운영' 카테고리의 다른 글
| Metricbeat 설치 및 Kibana 연동 (0) | 2021.05.27 |
|---|---|
| linux 환경 변수 세팅하는 방법 (0) | 2021.05.17 |
| 윈도우 Logstash 에서 Kinesis 연동하기 (0) | 2021.03.31 |
| Jenkins 및 Jenkins 콘솔에서 한글 깨짐 현상 수정 (0) | 2021.03.24 |
| windows + Jenkins + Bonobo git server+ slack (0) | 2021.03.23 |

