
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 연동
- nodejs
- build
- AWS
- MSSQL
- ssh
- API
- MySQL
- mariadb
- unity
- s3
- error
- Linux
- JS
- docker
- logstash
- JavaScript
- sample
- elasticsearch
- Ai
- 유니티
- 설정
- Kibana
- Python
- SSL
- Windows
- ChatGPT
- 구글
- 영어
- Today
- Total
목록AWS (46)
가끔 보자, 하늘.
링크만 올려둡니다. 안보신 분들 있으면 쭉 둘러보세요. :) https://kr-resources.awscloud.com/aws-reinvent-recap-kr-on-demand?trk=f4745311-27bb-4169-b1ce-8ffde15f86e7&sc_channel=em&mkt_tok=MTEyLVRaTS03NjYAAAGRAS0aC5kj-YbmBiOWKw04Kyk43FUATL4MR5fr00EdzFWlXT6XXf_EWDCQLzQhHyHpSPypqLt_hueayOYsvaibloe13njO1DLEuMMCH6WIdjYcmgk
 AWS Glue, Athen, Quicksight 첫 사용기
AWS Glue, Athen, Quicksight 첫 사용기
Data pipeline 을 AWS로 마이그레이션 하려고 관련 제품들을 살펴보는 중입니다. 기존 프로세스를 어떻게 AWS로 가져올지를 검토하기 위해 알아볼 겸 간단히 정리해 보겠습니다. 현재는 각종 서비스의 데이터를 가져오기 위해 시기에 따라 제작하여 운영해오고 있었기 때문에 서비스 별로 서로 다른 pipeline을 사용하고 있습니다. 예를들어 데이터 수집을 위한 (1) 전용 api server를 만들고, (2) 데이터 손실 방지를 위해 redis에 일정 기간 저장/백업 후 자동 삭제, (3) 이를 logstash로 정기적으로 가져와 (4) Elasticsearch에 저장, 다시 이를 (5) DW에 가공하여 저장, 일부는 실시간 지표 확인을 위해 (6) S3에 저장, 모바일/웹에서 (7) 뷰어를 제공해 ..
 S3 Glacier 에 데이터 백업하기
S3 Glacier 에 데이터 백업하기
예전에 중요한 데이터가 있을때는 (라떼는... -_-;) CD로 백업을 했더랬지 말입니다. 하지만 그걸 복구하는건 요원한 일이 되어가고 있네요. 그래서 최근 중요 데이터를 S3에 백업하며 겪었던 내용들을 간단히 정리했습니다. 1. 기본 옵션 설정 AWS 웹 콘솔에서 S3로 가 버킷을 생성할 때 공식 문서(https://aws.amazon.com/ko/getting-started/hands-on/getting-started-using-amazon-s3-glacier-storage-classes/)에는 잠금 설정, 버전 관리 활성화 등의 옵션에 대한 언급이 있으나 필수 옵션은 아닙니다. 하지만 덮어쓰기, 실수로 삭제되는 휴먼에러에 대응하기 위해서는 꼭 필요한 옵션입니다. 또한 버킷 생성 시 잠금 설정을 하지..
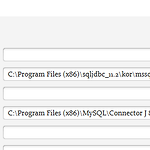 AWS SCT 사용법 정리
AWS SCT 사용법 정리
최근 아주 오래된 MSSQL DB (2008 R2)를 MySQL로 마이그레이션 작업을 하면서 AWS SCT(Schema Conversion Tool)를 사용해며 관련 내용을 정리해 보았습니다. 이 링크에서 SCT 설치파일과 사용할 JDBC 드라이버를 다운받아 설치합니다. 그리고 Settings -> Global Settings -> Drivers에서 MSSQL과 MySQL 드라이버를 설정합니다. 그리고 상단 메뉴에서 File -> New Project 를 선택해 새로운 프로젝트를 생성합니다. MSSQL 2008 R2는 SCT에서 지원하지 않습니다. 별도 MSSQL 라이센스가 없어도 AWS Console -> RDS에서 Free tier로 SQL 서버를 생성해 사용 후 삭제하면 거의 비용이 들지 않습니다...
인스턴스의 메타데이터란 실행 중인 인스턴스를 구성 또는 관리하는 데 사용될 수 있는 인스턴스 관련 데이터입니다. (link) 예를들어 현재 실행중인 인스턴스가 어느 리전에 속해 있는지를 알고 싶을 경우 사용할 수 있습니다. 환경변수로 설정하려면 각 리전별로 배포 프로세스를 분리해야 하지만 메타 데이터로 자신의 리전을 확인할 수 있으면 보다 간단히 해결할 수 있습니다. 메타 데이터를 확인하는 방법은 이 링크에 상세히 설명되어 있습니다. 여기서는 curl로 원하는 정보를 콘솔에서 확인하는 방법을 알아보고, python code로 처리하는 방법을 살펴보겠습니다. 우선 원하는 지역에 EC2 Instance를 하나 만들고 원격 접속을 합니다. 그리고 아래와 같이 입력해보세요. (169.254.169.254는 인스..
CDK로 RDS 생성 시 관리자 인증을 Secret Manager를 아래와 같이 설정하고 RDS 생성시 credential을 등록할 수 있습니다. import * as rds from 'aws-cdk-lib/aws-rds'; import { Credentials, DatabaseInstance, DatabaseInstanceEngine, DatabaseSecret, MysqlEngineVersion } from 'aws-cdk-lib/aws-rds' const vpc = new ec2.Vpc(this, _id); const instanceIdentifier = 'mysql' const credsSecretName = 'rds-pw' # rds를 위한 credential을 생성 const creds = n..
 Linux에서 AWS ECR Docker 이미지 설치하기
Linux에서 AWS ECR Docker 이미지 설치하기
우선 aws congifure 설정이 필요합니다. 이와 관련된 내용은 이 링크(link)를 확인하시면 됩니다. 사용하는 계정에는 ECS Access 권한이 필요합니다. docker 설치 및 실행 우선 도커를 설치하면 됩니다. (아래 내용은 AWS Linux2를 기준으로 설명합니다.) sudo yum install docker -y sudo systemctl start docker 그리고 ec2-user에 docker group 권한을 설정합니다. sudo usermod -a -G docker ec2-user 설정 후 재접속해서 id 명령으로 ec2-user 계정에 docker 그룹이 할당된 것을 확인합니다. 이제 ecr 인증을 진행합니다. aws ecr get-login-password --region ..
 CDK로 AWS 인프라 구축하기 - #마지막
CDK로 AWS 인프라 구축하기 - #마지막
원래 #5로 끝났지만 주의할 사항들이 몇 있어 간단히 정리하고 정말 마무리 하려 합니다. 1. 여러 스택을 정의한 경우 > cdk deploy/destroy stack01 // 이렇게 명시해서 특정 스택만 배포/삭제 > cdk deploy/destroy --all // 정의된 모든 스택을 배포/삭제 2. 분기 처리 방법 local의 config, env 파일 등에 정의한 내용을 활용하여 내부 분기처리를 할수 있습니다. 예를들면 config.json 파일에 배포할 지역을 정의하고 이를 읽어 처리할 수 있습니다 // config.json 의 예 { "regions" : ["us-east-2", "ap-northeast-2"] } 혹은 위와 같은 내용은 ddb에 업데이트하고 deploy/destroy 시 이를..